이번 챕터에서는 CPU의 구조와 함수에 대해 알아보겠습니다.
CPU 의 구조
-ALU
-Registers
-Control
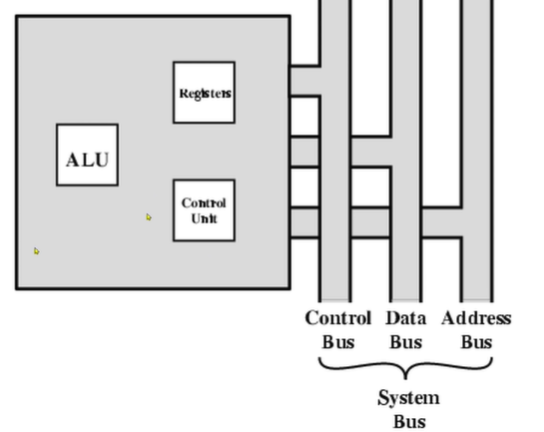
좀 더 자세하게 ALU의 내부 구조를 살펴보겠습니다.

ALU 는 어떤 연산을 사용해야합니다. 그래서 안 쪽에는 여러 연산을 수행시킬 수 있는 Logic 이 존재합니다.
만약 0, negative, overflow 가 발생되면 Status Flags 가 나갑니다.
기본적인 operand 는 외부 Register 에 저장이 됩니다.
Registers
는 temporary storage입니다.
내부 저장은 1클럭입니다. 외부면 몇백 클럭이 됩니다. 단점은 너무 비싸다는 거죠.
-User visibel register : 사용자에게 보이는
Getneral Purpose : 많이 쓰면 flexibility 올라가고 complexity 해집니다. Special은 반대입니다.
Data
Address
Condition Codes
Register 의 크기는 word 의 크기에 의해 결정이 됩니다.
-Control and status : 제어신호에 의해만 보임 (매우 중요)

Program Status Word
PSW 는 일반적으로 몇개의 비트를 setting 할 수 있는 형태로 구성이 되어 있습니다.
Includes Condition Codes(CCR)
아래와 같은 상황이 생겼을 때 해당 상황이 셋팅이 되는 겁니다.
-Sign of last result( 음수 발생)
-Zero
-Carry
-Equal
-Overflow
-Interrupt enable/disable, interrupt mask
-Supervisor 비트도 있습니다.
사용자에 의해서 임의적으로 설정이 되지 않습니다.
어떤 프로세서에는 H 라는 것도 존재하는데 이는 다양하고 효율적인 동작을 하게 합니다.
아래와 같은 PSW 에 대해 보겠습니다.

TRACE MODE : 디버깅으로 instruction 하나하나를 스텝바이스텝으로 실행시킬 때 동작
INTERRUPT MASK : 값을 설정함으로써 인터럽트를 받을지 말지에 대해 설정
그리고 연산 결과에 대한 셋팅은 CONDITION CODES 에서 됩니다.
이는 프로세서마다 다릅니다.
Supervisor Mode
-Intel ring zero
-Kernel mode
-Privileged instructions (우선 순위가 더 높은 명령어를 실행하게 해줍니다.)
-user 레벨에서는 사용이 안됩니다.

만약 indirect mode 라면 추가적으로 가져와야 합니다.

Data Flow(Instruction Fetch)
Fetch
- PC 다음 명령어 주소 포함
- 주소가 MAR 로 이동
- 주소가 address bus 에 위치함
- Control unit 이 memory read 에 요청함
- result 가 data bus 에 실림, MBR 에 복사 되고 해석되어야하니 IR 로 들어감
- 그리고 PC +1 이 됨

명확하게 이 기능들에 대해 알아야함
Data Flow(Data Fetch)

indirect addressing(간접 주소 방식) 에서는
operand 가 주소가 됩니다.

- Right most N bits of MBR transferred to MAR
- Control unit requests memory read (0x11 의 들어있는 값을 데이터버스를 통해 읽음)
- Result (address of operand) moved to MBR ( 데이터버스로 읽은 거기 때문에 MBR로 감)
- The address of operand moved to MAR again! (다시 0xFF를 읽음)
- Control unit request memory read ('A' 값을 읽음)
- Result(data operand) moved to MBR
Data Flow(Execute)
많은 방식 들이 있음
Data Flow(Interrupt) 자세히 봐야함
interrupt 는 보통 I/O device 입니다. CPU 가 인터럽트를 받으면 실행되고 있는 걸 저장하고(1)(stack pointer가 됨, 리턴주소) 인터럽트 루틴을 실행시켜야겠죠. 다음이 그 과정입니다.


Prefetch 개념에 대해 알아보겠습니다.
fetch 라는 건 메인메모리에 accessing 하는 거였죠.
Execution은 CPU 에서 실행을 시키는 겁니다.
이 둘은 충돌하지 않기 때문에 동시에 일어날 수 있습니다.
그러니 실행을 하는 중에 다음 명령을 미리 가져온다는 의미입니다.
-> 성능이 높아질 수 있기 때문입니다.
하지만 두 배의 성능이 향상되지 않습니다.
Execution은 길고 Fetch는 짧기 때문입니다.
이걸 좀 확대하면
Pipelining 이라는 개념을 가질 수 있습니다.
- 명령어를 가져오고
- 이를 해석하고
- operand를 계산하고 (계산의 의미를 operand의 위치를 파악한다는 말입니다.)
- operand를 가져옵니다.
- 명령어를 실행하고
- 결과를 씁니다.
이 걸 적절히 Overlap을 시키면 성능이 높아지지 않을까 하는 생각입니다.
그래서 Pipelining 의 의미를 increase throughput
즉 처리율을 상승시키는 기술입니다.

빨래를 한다고 할때 다음과 같은 과정이 있을 수 있습니다.
Case 1: Sequential Laundry

각 90분을 순차적으로 하면 6시간 걸렸습니다.
Case 2 : Pipelined Laundry
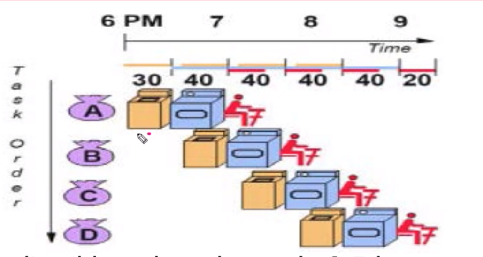
이러면 순차적 진행을 할 때보다 훨씬 적은 시간으로 모두가 빨래를 끝마칠 수 있습니다.
그럼 문제점은 뭘까요?
Prefetch를 했습니다. 근데 이 실행되는 명령어가 'Branch' 였다는 겁니다.
Branch는 순차적으로 실행이 안되고 조건에 따라 jump가 되는거죠.
어디로 점프할지는 동작이 실행되어야 알 수 있습니다.
이러면 prefetch 해온 instruction 을 버릴 수도 있습니다.

이제 실제 좀 더 정확한 명령어가 실행되는 모델을 가지고 Pipelining 을 보겠습니다.
일반적으로 stage 가 많아지면 speedup 됩니다.
- FI : Fetch instruction
- DI : Decode instruction
- CO : Calculate operands (operand 가 어디 있는지 계산)
- FO : Fetch operands
- EI : Execute instruction
- WO : Write result

파이프라인이 일어나는 과정을 보여주고 있습니다.
이러면 54번에 끝나는 일은 14번만에 끝낼 수 있습니다.
이제 용어를 정리하고 넘어가겠습니다.

K 는 각 instruction은 몇개의 작은 stage 로 나눠어졌는지. 여기에선 6입니다.
n 는 instruction의 개수입니다. 여기선 9입니다.
타워는 cycle time 으로 여기서는 14 입니다.

모델링을 하면 다음과 같습니다.

n을 무한대로 보내면 속도는 k 에 의존하게 됩니다.
이상적인 상황에서는 얼마나 잘게 쪼개냐에 의해 속도가 결정이 되는거죠.
Limitation by Branching
분기 때문에 미리 명령어를 끌어온게 아래 그림과 같이 아무런 도움이 안 될 수 있습니다.

만약 Instruction 3 의 conditional branch 가 15 로 jump가 되는 조건이 있습니다. ( 언제 어디로 튈지 모름)

여기서 branch 를 하게 된 겁니다. 그러면 Instruction 의 명령어를 미리 가지고 온 의미가 없게 됩니다.

또한 4,5,6,7 의 결과가 하나도 나오지 않습니다.
이제 Pipeline 을 사용할 때 또 다른 고려점에 대해 이야기 해보겠습니다.

위 코드를 보면 연산 결과가 D 로 갑니다. 이러면 파이프라인을 할 수 가 없습니다. 이전 명령어가 pipeline 에 있기 때문에 제약이 있을 수 밖에 없는 겁니다.
Pipeline의 성능
앞 전에서 stage 가 많아지면 속도가 높아진다고 했습니다.
하지만 이는 이성적인 경우가 현실적으로는 buffer때문에 overhead가 발생할 수 있습니다.
그리고 branch을 어떻게 다루는지에 대해 알아보겠습니다.
- Multiple Streams
- Prefetch Branch Target
- Loop buffer
- Branch prediction
- Delayed branching
Multiple Streams

다음은 branch 가 실행되고 있는건데 Multiple Streams은 간단하게 여기서 두개의 파이프를 쓰게 다는 겁니다.
문제는 많은 경우의 수가 있는 경우에는 브랜치를 효과적으로 처리 할 수 없습니다.
Prefetch Branch Target
조건문이 있을 때 브랜치들을 prefetch 하고 이 Branch가 실행될 때까지 유지하는 겁니다. 오버헤드가 많이 발생하겠지만 Multiple Streams 보다는 현실적인 방안입니다.
Loop buffer

아주 빠른 메모리가 fetch stage 를 관리가 됩니다.
이는 조건을 관리하는 부분을 이 메모리에 넣는겁니다.
캐시와는 좀 다르고 대응을 빠르게 하겠다는 의미 입니다.
이렇게 Branch penalty 를 줄이겠다는 게 핵심입니다.
Branch Prediction
예측을 해서 하겠다는 의미 입니다.
예측 기술
(1) Static : Branch는 일어나지 않는다, 무조건 일어난다. opcode 를 쓰면 일어난다. -> 정적인 방법
(2) Dynamic : Taken/Not Taken 상황에 따라 바뀜 ,branch history table 을 계속 만들면서 추적
Taken/Not Taken 기법


첫번째로 branch 가 일어날거라 생각해서 계속 예측하는 겁니다. 예측이 맞으면 기뻐하다가 만약 한번 틀렸다면

그래도 다음에는 일어날거야! 라는 생각으로 다시 Branch 가 일어날거라고 예측합니다. 일어나면 다시 첫번째 원으로 돌아오겠죠. 하지만 두번 연속 Branch 가 일어나지 않았을때

이제 안 일어날거야! 에 투자를 하게 됩니다.

위 그림은 Branch 가 never taken 일거야 할때 기본 동작이 1 : 다음 명령어 실행 입니다.
2 번은 예외가 발생했을 때 그 예외를 처리하는거죠.
Dealing With Branches - Branch history table
이제 조금 더 복잡한 Branch histroy table 에 대해 알아보도록 하겠습니다.

어떤 코드에서 Branch 명령어가 중간중간에 있을 겁니다. 이를 Branch instruction address 에 적어두는 겁니다 .

이게 일어났는지 안 일어났는지를 Target address , state 에서 체크를 할 겁니다.
이런 테이블을 계속 업데이트해서 다이나믹하게 해서 예측 확률을 높이는게 전략입니다.

Select 는 (a) 순차적 주소와 (b) table 로 부터 나오는 address 입니다.

table은 cache 처럼 작동이 됩니다. Target address 에는 예측되는 Branch 가 들어 있습니다.
(a) 만약 Branch 가 실행 되었을 때 table 에 맞는 게 없다면 Select 에서 순차적으로 가자 하고 들어가는 겁니다.
(b) 만약 table 에 맞는게 있다면 table 에 해당되는 instuction 을 가지고 옵니다.

Branch 명령어가 쭉 실행이 됩니다.
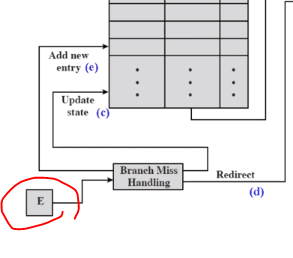
E가 Signal 을 table 에 보냅니다.
(c) 예측 했던 instruction 이 아니더라 맞더라 -> Update
(d) incorrect 하면 해당되는 걸 가지고 와야 합니다. 해당되는 걸 update 해줍니다.
(e) 어떤 조건 branch 를 했는데 없었을 때 새로운 항목으로 넣어주어야합니다. 'Branch instruction address' 에
'공부 > 컴퓨터 구조' 카테고리의 다른 글
| 컴퓨터구조14 Instruction Level Parallelism and Superscalar Processors (0) | 2020.07.03 |
|---|---|
| 컴퓨터구조13 Reduced Instruction Set Computers (0) | 2020.07.03 |
| 컴퓨터구조11 Instruction Sets : Addressing Modes and Formats (0) | 2020.06.30 |
| 컴퓨터구조10 Instruction Sets : Characteristics and Functions (0) | 2020.06.29 |
| 컴퓨터구조9 Computer Arithmetic (0) | 2020.06.23 |



