Superscalar 가 뭔지는 그림을 보면 바로 느낌이 옵니다.
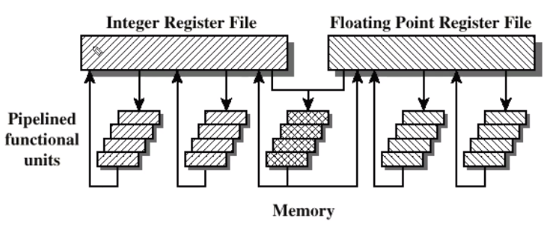
정수형정보를 가지는 레지스터들과 실수형 레지스터 파일도 두개 입니다.
superscalar는 간단히 ALU 가 두개 라는 겁니다.
이러한 명령어들이 독립적으로 실행이 되어야합니다.
RISC 에서 보통 많이 쓰고 CISC 에서도 가능
필요한 이유는 RISC에서 스칼라 계산이 많기 때문입니다.
Superpipelining
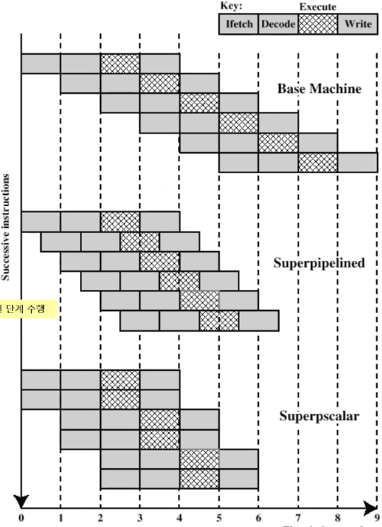
가운데 부분이 superpipeline입니다.
이는 하나의 클럭으로 움직이는 게 아니라 반 클럭으로 파이프라인이 가능하게 한 겁니다.
Superscalar는 두개가 동시에 일어나고 있는걸 볼 수 있습니다.
Limitations
이런 것들이 다 명령어 수준에서 parallelism 을 실행하는 겁니다.
Instruction level parallelism(ILP)
ILP 을 수행하기 위해서 다음과 같은 제한이 있습니다.
- True data dependency
- Procedural dependency
- Resource conflicts
- Output dependency
- Antidependency
True Data Dependency
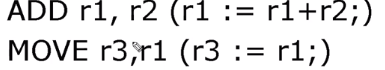
파이프라인을 쓰지 않으면 첫 줄 실행되고 그다음 두번째 줄이 실행이 됩니다.
하지만 파이프라인을 쓰면 다릅니다.
즉 첫번째 줄의 r1 이 다음 줄에 r1 과 의존하는 형태이기 때문에 타이밍을 안 맞추면 엉뚱한 값을 받게 됩니다.
이것을 'True Data Dependency' 라고 합니다.
Procedural Dependency
branch랑 명령어를 실행시킬 때 분기에 따라서 뒷 내용이 변할 수도 있거나 뛰어넘을 수 있습니다. 그러니 미리 분기로 해도 의미가 없습니다.
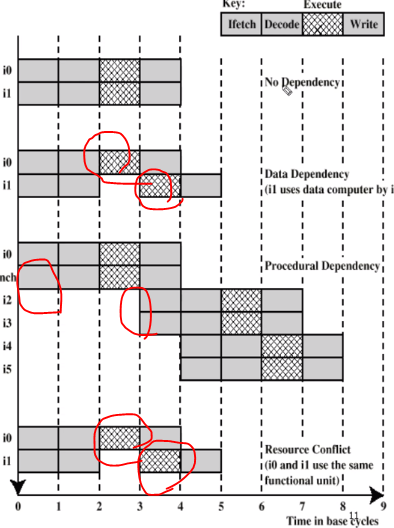
Resource Conflict
리는 두개 이상의 명령어가 리소스를 쓰겠다고 경쟁을 일으키는 겁니다 .
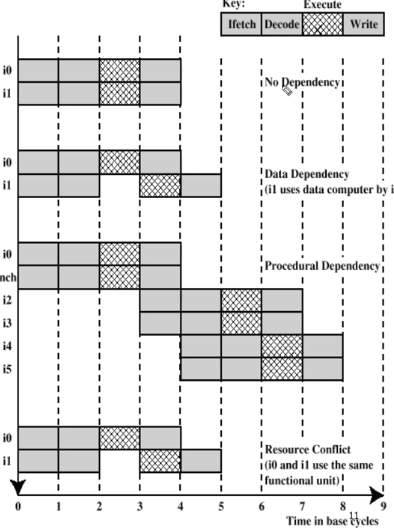
superscalar 식으로 파이프링이 일어나고 있습니다.
Data Dependency 는 첫번째 결과가 나와야 다음 결과가 나오니깐 다음과 같은 겁니다.
Procedural Dependency는 브랜치 이전과 이후에 실행이 가능한다 동시에는 절대 실행할 수 없습니다.
Resource Conflit 는 Execution 하는게 하나밖에 없어서 경쟁으로 선점하고 나눠서 하는 겁니다.
Design Issues
Instruction level parallelism
명령어만으로 병렬처리 가능 -> 실행유닛이 두개 이상이고, 디코더, 페치같은게 다 두개 이상일때 가능해집니다.
연속적으로 된 명령어가 독립적이라면 실행은 overlap 될 수 있습니다.
Machine Parallelism
Instruction Issue Policy
명령어를 이슈화
이는 명령어를 실행시키기 위해서 준비를 하는 과정입니다.
이런 정책이 있는 이유
실행을 할 수 있는 엔진 여러개
제한도 있고 우리가 낼 수 있는 최적의 알고리즘을 위해 그리고 우리가 의도한 결과가 나와야합니다.
이 세가지 요인을 고려해서 실행을 시켜야합니다.
고려할 요소들

명령어 어떻게 페치 , 실행되냐 ( 순서중요 ). 명령어 레지스터 메모리 변화
Superscalar
실행엔진이 여러개인 걸 극대화 시켜서 성능을 올려야함
- In-order issue with in-order completion : 어떤 프로그램이 있으면 원래 순서를 유지해서 바인딩 , CPU 에서는 받은 순서대로 실행을 시켜서 끝을 내겠다.
- In-order issue with out-of-order completion : 원래 순서대로 받고 순서를 바꿔서 효율적으로 시행시킴
- Out-of-order issue with out-of-order completion : 처음부터 순서바꿔서 실행도 순서바꿈
이 세가지 정책에 대해 자세히 알아보겠습니다.
In-order issue with in-order completion
예상할 수 있듯이 그렇게 복잡하지도 않고 그렇게 효율적이지도 않습니다.


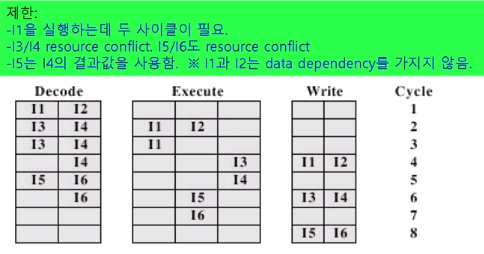
I3/I4 -> 동시 처리 불가 (병렬 불가)
I5/I6 도 동일 , i5 도 i4 동시 실행 불가 True data dependency 존재
보면 I1과 I2를 동시에 실행시킵니다. I3 는 두 클럭이 걸리고 I4는 세 클럭이 걸렸습니다. 이는 명령어마다 다릅니다.
그 순서대로 이슈잉을 합니다. Execute 를 보면 동시에 실행할 수 없어서 다음과 같이 실행한 것을 알 수 있습니다.
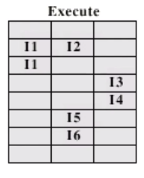
In-order issue with out-of-order completion
여기서 우리가 집중해야하는 개념이 있습니다.
'Output dependency' 입니다.
true data dependency 는 어떤 결과물이 있을때까지 그걸 읽으면 안되는 겁니다.
여기서 I1과 I2 가 동시에 수행하면 될까요? 여기서 Data dependecy 가 없기 때문에 동시에 실행해도 상관은 없습니다. 여기서 문제가 뭐냐면 이 순서를 유지하지 않고 I3 을 먼저 실행시켰다고 생각합시다. 그럼 I1으로 의해 오는 결과를 틀릴 겁니다. 이것을 output(write-write) dependency 가 있다고 합니다.

만약 이때 결과가 바뀌지 않으면 먼저 실행을 해도 됩니다. 그게 Out-of-order completion입니다.
하지만 위 예시 같은 코드는 순서를 바꾸면 안됩니다.
즉 output dependency 가 있을 때는 Out-of-order completion 하면 안 됩니다.

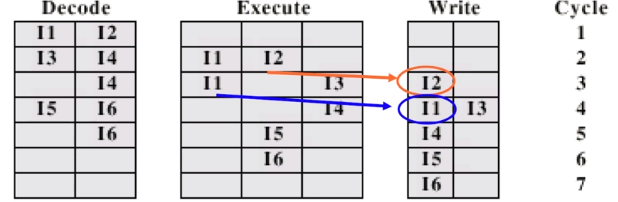
이전 사이클보다 1사이클 적습니다. 보면 이전에서는 I1과 I2 가 같이 Write 가 나옵니다. 하지만 여기서는 가정에서 data dependency 가 없다고 했기 때문에 I2 결과를 3 에서 Write-back 하는 겁니다. (I2가 먼저 끝나기 때문에)

Out-of-order issue with out-of-order completion
여기서는 이슈잉 부터 순서를 바꿉니다.


여기서는 Decode 단계와 Execute 단계를 분리를 하자는 겁니다. 원래 됐었습니다. 근데 지금 왜 이렇게 하냐,
전에는 Decode 이 되면 그거 대로 fetch 를 했는데 이제는 Window 라는 걸 만들어서 순서를 바꾸고 Execute 하겠습니다. 이야기 입니다. 여기서 dependency 같은 걸 분석을 합니다.


우리가 고려해야할 또 다른 사항에 대해 알아보겠습니다.
Antidependency
True dependency 와 반대의 개념입니다.
또 Write-after-read dependency 라고도 합니다.
이는 쓴 다음에 읽어라는 의미입니다.

그림을 위에서 아래로 실행하면 문제가 없습니다. 만약 이 순서를 뒤 바꾸면 문제가 생깁니다.
그러니깐 먼저 읽어라는 겁니다.
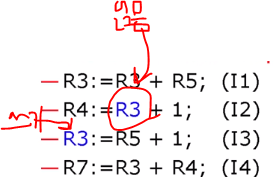
이 개념은 True 와는 정반대입니다. True는 다음과 같았습니다. 쓴 결과를 읽어라
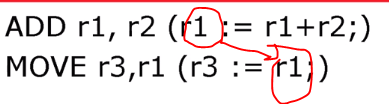
또 다른 전략으로 Register Renaming 이라는 것이 있습니다.
이 기법은 금방 본 antidependencies 와 output dependencies 를 해결할 수 있습니다.
즉 필요할 때 레지스터를 추가해라는 의미입니다. 즉 같은 r3 가 여러 개 있고 이를 필요할 때 사용하라는 의미입니다.
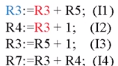
이 코드를 리네임 한 결과입니다.

원래 코드에선 R3 가 하나밖에 없는 거처럼 보이지만 Renaming 에서는 세개를 사용합니다.

이런 식으로 Write-after-read 도 해결해주고 있습니다.

ILP에 대해 배워보았습니다.
'공부 > 컴퓨터 구조' 카테고리의 다른 글
| 컴퓨터구조17 Parallel Processing (0) | 2020.07.03 |
|---|---|
| 컴퓨터구조15 Control Unit Operation (0) | 2020.07.03 |
| 컴퓨터구조13 Reduced Instruction Set Computers (0) | 2020.07.03 |
| 컴퓨터구조12 CPU Structure and Function (0) | 2020.06.30 |
| 컴퓨터구조11 Instruction Sets : Addressing Modes and Formats (0) | 2020.06.30 |



