이번 챕터는 RISC Processor 에 대해 살펴보도록 하겠습니다.
Reduced Instruction Set Computers
이는 명령어 셋이 축약된 형태라는 겁니다.
주요 특징
-레지스터 많음
-소프트웨어 중요성 커짐 = 컴파일러
-간단한 명령어 셋트 (중요) 이를 파이프링하고 최적화 해서

CISC 가 어떻게 나왔는지에 대해 먼저 알아보겠습니다.
Complex Instruction Set Computers
하드웨어는 발전했지만 부족한 소프트웨어의 기술은 약했습니다.
그래서 기능이 필요하면 하드웨어를 만들고 필요한 Instruction set 을 추가로 더 만들자 하는 방식을 취했는데 이게 CISC 입니다.

즉 high level languages 을 하드웨어로 바로 구현해버리는 거
- 컴파일러가 쉽고
- 실행도 효율적인 거처럼 보임
- 상위 레벨 언어 서포트
몇몇 연구자에 의해서 다른 관점에 연구가 시행됐습니다. -> RISC 가 탄생
- Operations perfomed : 기능 결정
- Operands Used : 연산 특성 분석
- Execution squencing : 프로그램 동작 플로우 관점 분석
이를 Dynamic studies 입니다.
그래서 다음과 같은 Operations 을 분석했습니다.

그래서 다음과 같은 결과가 나왔습니다.
Dynamic Occurrence 는 그래서 얼마나 자주 일어났는지 확인하는 겁니다. 분석하니 (ASSGIN 과 IF 가 많았다는 걸을 알 수 있습니다.)
Machine-Instruction Weighted 는 발생 비율입니다. ( 함수 CALL) 그럼 시간적으로 함수 CALL 이 제일 큰 비중을 차지하는구나를 알 수 있습니다.
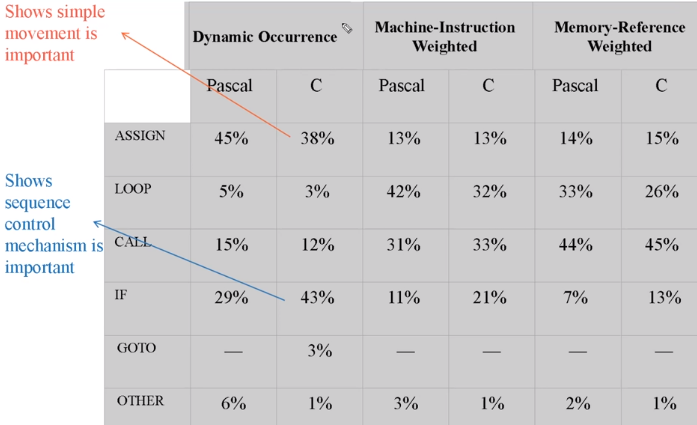
그럼 이렇게 시간이 가장 많이 걸리는 Operations 을 빨리 시행시키자라는 관점으로 연구가 진행이 됐을겁니다.
Operands 관점에서는 다음과 같습니다.
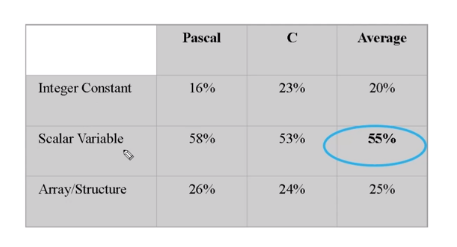
Procedure Calls
이 가장 시간을 오래 걸린다는 것을 알았습니다.
그리고 재귀로 이루어지면 Nesting 으로 계속 들어갑니다.
또 리턴값은 그리 많지 않고 대부분의 변수는 지역 변수라는 것을 알았습니다.
Tanenbaum's study 입니다.
이 연구를 통해 HLL 와 비슷하게 만드는 건 그다지 효율적이지 않다는 것을 알아냅니다.
그래서 나온게 RISC 입니다.
- register 많음 -> 컴파일러의 역할 커짐
- piplining
- 짧고 간단
수많은 레지스터를 묶어서 Register File 라고 부릅니다.
변수가 빠른 레지스터로 할당이 많이 되었기 때문에 memory access 하는 시간이 많이 줄어들었습니다. (성능 업)
Register Window
레지스터 파일을 어떻게 효과적으로 지역변수와 함수를 콜하는 파라미터, 리턴하는 변수에 사용할 수 있도록 만드느냐와 관련된 겁니다.
- locat 변수 레지스터 할당
- 파라미터 패스
- 결과 리턴
--> 다 레지스터의 할당
어떤 구조를 취해야 이 세 가지 변수를 가장 많게 할당할지에 대한 이슈가 생김
--> register windows
register windows 는 세가지 파트를 가집니다.
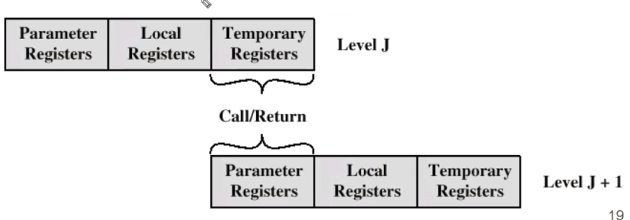
Temporary Registers 는 call/return 을 넣는 건데 이는 내부적으로 또 다른 걸로 오버랩이 됩니다.
Circular Buffer Diagram
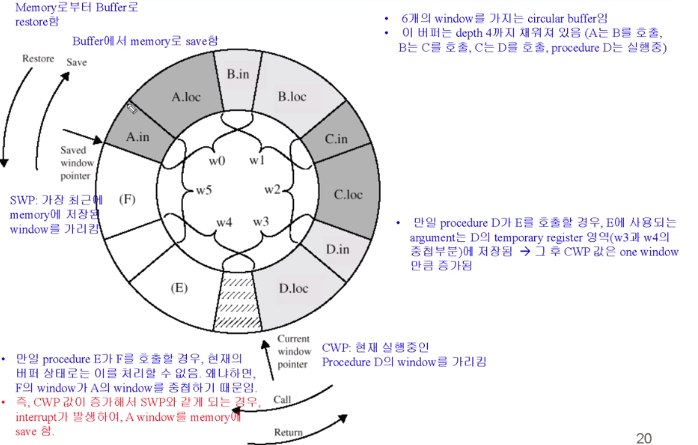
첫번째 버퍼에서 A라는 함수를 호출한다고 합시다. (메인함수로 봐도 됩니다.)
그리고 세번째에서 다른 함수를 Call 한겁니다. 이곳이 temporary 레지스터 부분이었습니다.
이렇게 연결이 되는 겁니다.
더 이상 추가가 안될 경우 그럼 첫 A 부분을 memory 로 이동을 시킵니다.
그리고 함수가 return return 될때 다시 이 부분을 버퍼로 가지고 오게 됩니다.
이를 위해서 CWP라든지 SWP 라든지 포인터를 사용하게 되는 겁니다. (이 두 포인터의 의미 파악 중요)
CWP : 현재 실행중인 Procedure 의 Window를 가리킴
SWP : 가장 최근에 memory 에 저장된 window 를 가리킴
그럼 이제 Global Variables 은 어떻게 할당을 할지에 대해 알아보겠습니다.
컴파일러가 결국 레지스터를 전역변수할당합니다.
Graph Coloring 으로 가능한 사례를 보도록 하겠습니다.

현재 사용이 되는 변수(레지스터) 이 두 개의 레지스터는 edge 로 연결, 즉 서로 다른 색깔은 다른 레지스터로 할당해야한다는 의미

Vertex 는 레지스터가 됩니다.
그럼 Edge 가 동시에 active 되어야할 걸 알려줍니다.
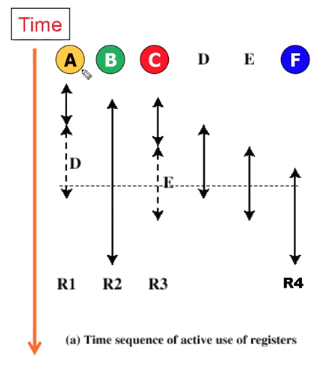
변수들마다 얼마의 시간동안 사용이 되는지를 보여주고 있습니다.
A 노랑색 컬러 색칠 -> 레지스터 할당
A 의 첫 할당이 끝나는데 이게 D와 맞물리니깐 그냥 이 레지스터에 할당하면 되겠다는 생각을 합니다.
C 와 E 도 마찬가지입니다.
그래서 같은 시간에 사용이 되냐 안되냐로 그림을 그린 것이 다음과 같습니다.
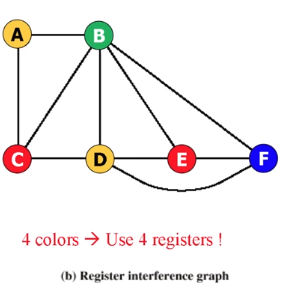
이렇게 레지스터 할당을 Graph Coloring 으로 해결할 수 있습니다.
CISC 의 장점
- 컴파일러 용이? -> 근데 잘 모르겠음. 명령어 개수 많아지고 크기도 다르고 실행시간 다 다름 -> 최적화 어려움
- 작은 프로그램? -> 물론 메모리 자체는 적게 씀 , 하지만 지금 메모리 가격이 쌈
- 빠름 ? -> 잘 모르겠음
RISC 장점
- 컴파일 최적화
그래도 완전히 RISC 가 좋은 건 아님
다음은 RISC의 특성입니다.

RISC Pipelining
두 단계 실행
- I : Instruction fetch
- E : Execute
load and store 추가
- D : Memory
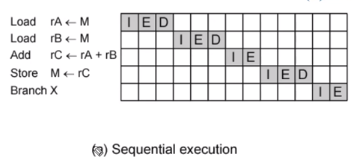
다섯개의 명령어를 순차적으로 으로 쭉 실행이 됩니다.
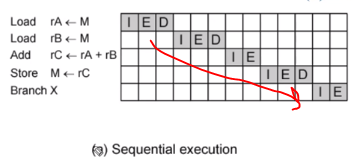
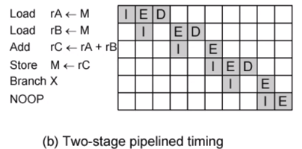
time 관점에서 execution 과 i(Pulse) 가 오버랩이 됩니다.
execution 은 코어와 i는 메모리와 코어 사이 관련 동작이기 때문에 같이 사용이 가능합니다.
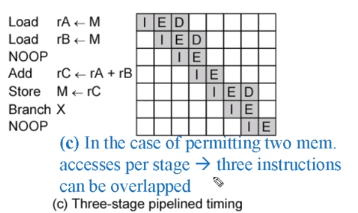
근데 D는 memory r/w 고 fetch 도 메모리 관련인데 두개 동시에 접근 할 수 있을까요?
가능하다고 가정을 한 겁니다.
그저 동시적 접근이 가능하다면 효율적으로 실행할 수 있다는 걸 보여주기 위한 겁니다.
하지만 동작마다 시간이 달라질 수 있으니 실제로는 다를 가능성이 높습니다.
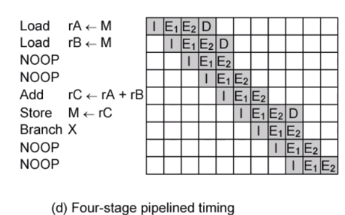
E를 다음과 같이 쪼개버린 겁니다.

Optimization of Pipelining
-Delayed branch
delay slot : 은 명령어 슬롯입니다. A, B 슬롯이 있을 때 B가 A 에 전혀 영향을 받지 않는 겁니다. 그럼 A 가 어떤 명령어이어야할까요?
A가 Branch 명령어라고 한다면

원래 JUMP 명령어라고 하면 105로 점프를 하기 때문에 103 이 시행이 되지 않을 겁니다. 결국엔 105 로 가기 때문입니다. 이런 특성. JUMP 뒤에 있는 슬롯을 유익하게 쓰겠다는 겁니다.
지금 같은 경우는 전혀 유익하지가 않습니다.

다른 예를 한번 보겠습니다.

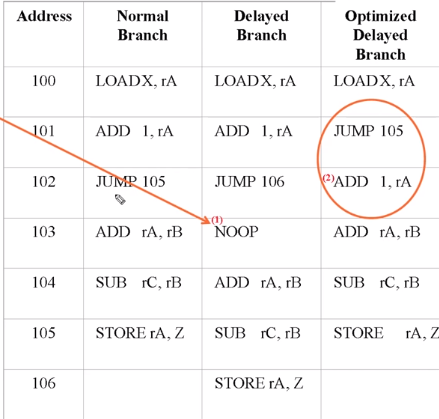
Optimized Delayed Branch 를 보겠습니다.
원래 는 100 에서 rA를 Load 하고 101 에서 1를 더한 다음 점프 후 105 에서 Z에 저장을 했습니다.
근데 여기서는 101과 102 의 순서를 바꿔보았습니다.
파이프라인에서 101이 실행될때 102도 동시에 실행이 되면 Add 가 됩니다. 그러고 105 번지로 실행이 되는 겁니다.
그림을 보면 이해가 될 겁니다.

파이프라인 식이라는데 의미가 있는겁니다. 보면
3 D 밑에 비워져있습니다. 이는 아직 첫번째 명령어에서 레지스터로 값이 써지지 않았기 때문에 비워둔 겁니다. 그래서 더하는 행위는 4에서 실행이 되는 겁니다.
여기서도 102 에서 105로 점프를 하기 때문에 103 은 실행이 되지 않습니다. 명령어 페치를 안해도 되는 부분입니다.
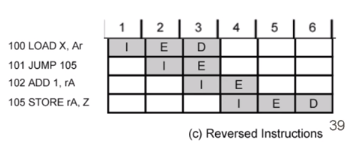
점프와 더하기의 순서를 바꾸고 필요없는 103을 빼버렸습니다.
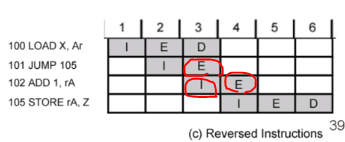
보면 점프를 진행할때 ADD 명령어 페치해서 E 까지 실행이 됩니다. STORE 가 되기 전에 말이죠.
그렇기 때문에 결과가 동일합니다. 즉 더 효율적이어진거죠.
이것이 Delayed Branch 효과입니다.
아래 그림은 이같은 것과 좀 다릅니다 .
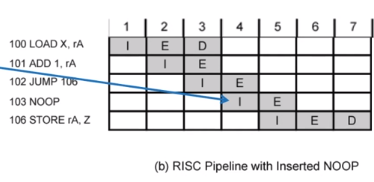
NOOP 는 No operation 입니다. 실행되도 아무런 상관이 없는 것을 집어넣어서 굳이 소프트웨어 쪽으로 파이프라인을 제어할 필요가 없게 하는 겁니다.
RISC 가 끝이 났습니다. 수고하셨습니다.
'공부 > 컴퓨터 구조' 카테고리의 다른 글
| 컴퓨터구조15 Control Unit Operation (0) | 2020.07.03 |
|---|---|
| 컴퓨터구조14 Instruction Level Parallelism and Superscalar Processors (0) | 2020.07.03 |
| 컴퓨터구조12 CPU Structure and Function (0) | 2020.06.30 |
| 컴퓨터구조11 Instruction Sets : Addressing Modes and Formats (0) | 2020.06.30 |
| 컴퓨터구조10 Instruction Sets : Characteristics and Functions (0) | 2020.06.29 |



