안녕하세요. 옆집 컴공생입니다. 많은 과목이 그러하듯 열심히 들어온 데이터통신도 뒤로 갈 수록 너무 어렵네요. 수식이 등장해서 그런걸까요.. 점점 수업이 무서워집니다. 그래도 좋은 점수를 받기 위해 복습도 철저히 해야겠죠?
오늘 복습할 건 'Formatting and Source Coding' 입니다.
강의목표는 다음과 같습니다. (강의목표는 항상 중요하게 봐두어야합니다.)
▶문자, 음성, 이미지 등의 정보를 Digital Data Formatting 하는 주요기법을 이해한다.
- Code, Encoding/Decoding, CODEC
- Digital Information -> Digital Data ex) 한글코드
- Analog Information -> Digital Data ex) PCM Modulation
▶Data를 효율적으로 표현하기 위한 Source Coding
- Compressor/Decompressor, CODEC
- 멀티미디어 데이터의 크기
- Digital Audio/ Digital Video 압축
그럼 시작해보겠습니다. 디지털 정보를 디지털 데이터로 바꾸는 예는 다음처럼 여러개가 있습니다.
1. Coding Schemes(Encoding/Decoding, CODEC)
2. 여러 문자(ASCII, EBCDIC... 음수는 2의 보수로 표현)
3. MIDI , 전자 음악 인터페이스입니다. 보통 음악 관련은 아날로그 정보라고 생각하기 쉬운데 이는 디지털정보입니다.
4. 한글코드 (완성형, 조합형?,UNICODE)
여러분은 한글을 표기하는 문자방식이 여러가지가 있다는 걸 알고 계셨나요?
1. ANSI
2. UTF8
3. UTF16BE
4. UNICODE
등이 있습니다.
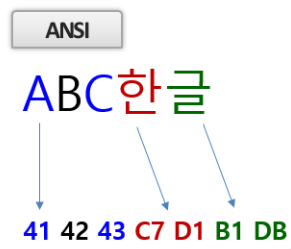
▶다음은 ANSI에서 한글을 표현하는 방식합니다. 영어는 2바이트, 한글은 4바이트로 표현되는걸 볼 수 있습니다.
▶다음은 UTF8 표현 방식입니다. 영어와 한글이 다 3바이트로 표현되고 있습니다.

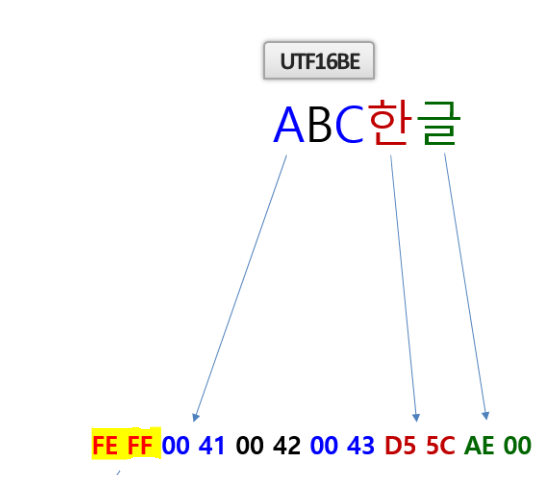
▶다음은 UTF16BE 표현 방식입니다. 영어와 한글이 다 2바이트로 표현되고 UTF16 인코딩을 알 수 있는 Marker 가 앞에 있습니다.
▶다음은 Unicode 입니다. 유니코드는 '세상의 모든 문자를 표시하기 위한 표준 코드 체계를 만들자' 는 취지로 발명됐는데요.
ASCII CODE 가 하나의 알파벳 문자를 1 Bytes로 Mapping 하는 것과
달리 UNICODE 는 하나의 문자를 2Bytes로 Mapping 합니다.
한국은 조합형/완성형 논쟁을 겪고 문자 코드의 중요성을 느껴 유니코드 표준화에 적극적으로 참여해 유니코드 영역을 많이 확보했습니다.(자랑스럽습니다.)
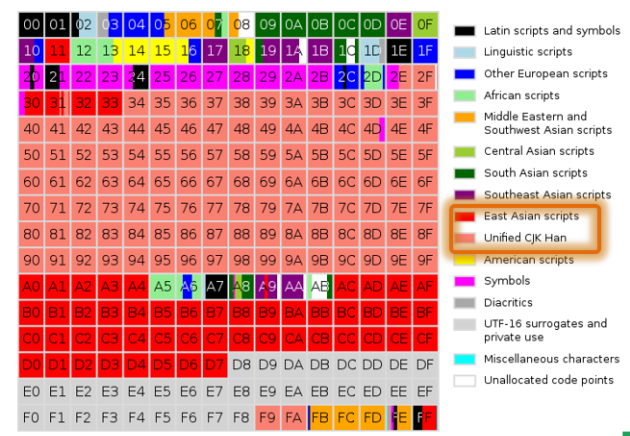
하지만 슬프게도... 영어 쓰는 사람들이 자기들이 2 바이트쓰기는 그랬나봐요... UTF로 인해 영문자는 1byte, 한글은 아쉽게도 3bytes 가 되었습니다.
Data Acquisition System
하드웨어 수준에서 구현된 ADC(analog signals to digital signal Convertor) , DAC(Digital signal to Analog signal Convertor) 입니다.
Sensor 와 Actuators 가 Transducers 입니다. 즉 이 두개가 입력 에너지와 출력 에너지를 다르게 한다는 뜻입니다.
그리고 Signal Conditioning 은 불필요한 신호를 제거해줍니다.

Analog Info -> Digital Data 에는 다음과 같은 종류가 있습니다.
▶소리
- PCM(Pulse Coded Modulation)
- Sampling Rate, Bits/Sample, Channel
▶이미지
- Pixel, RGB, Bits/Pixel
- VGA(640 * 480), QVGA, CIF(352 * 288), QCIF
▶동영상
- Frame, 24/30 FPS
- 480p, 720p, 1080i,1080p...
Pulse Code Modulation(PCM)
아날로그 소리 정보를 디지털 데이터로 바꾸는 PCM에 대해 배워보겠습니다.
여기서는 엄청 유명한 이론이 이용된다는데요.
바로 'Nyquist Sampling Theory' (나이퀴스트 샘플링 이론) 입니다.
이는 일정한 간격에 따라서 가장 높은 주파수에 두배를 샘플링하면 모든 정보를 복구할 수 있다는 이론입니다.
샘플링 된 거에 값을 부여하는 과정을 거치면, 즉 값이 이산적으로 Discrete 해지게 하는 과정을 Quantization(쿼터제이션), 양자화라고 합니다.
아날로그 -> 데이터 과정은 다음과 같습니다.
Sampling -> Quantizing -> Encoding
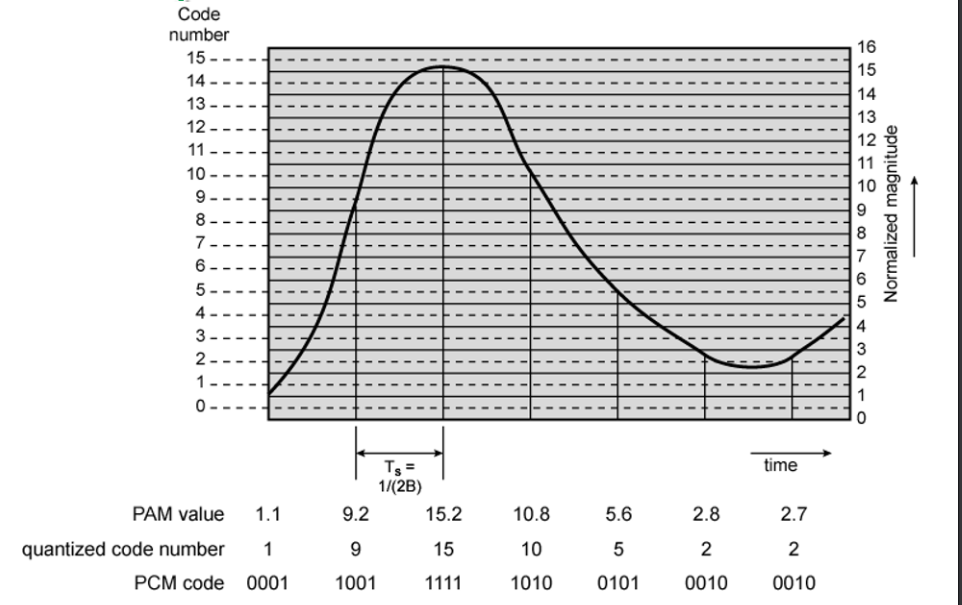
그래프 밑에 값을 보면 PAM value 가 quantized code number 로 값이 격자에 맞춰서 변하는 것을 볼 수 있습니다. 그리고 이 값을 이진 값으로 인코딩하는 걸 볼 수 있습니다.
멀티미디어 정보의 크기
》 48Khz, 16bits/Sample, Stereo(2 Channel) Digital Audio를 1시간 동안 녹음할 경우 발생하는 정보의 양은?
K가 10^3 이니깐 48000hz 로 한번에 16bits = 2 bytes 로 샘플링됩니다. 채널이 두 개임으로 1시간 동안 한다면
48000 x 2 x 2 x 3600 = 691,200,000
입니다. 딱봐도 정보량이 굉장히 많죠?
》또 VGA로 16bits/Pixel, 30FPS 비 압축 동영상의 초당 정보 발생량은 어떻게 될까요?
VGA는 640 x 480 픽셀입니다. 여기서 FPS는 초당 프레임의 수인데요. 동영상은 사진이 빠르게 넘어가는 형식이기 때문에 이런 개념이 있는겁니다.
그럼 정보량은 640 x 480 x 2(16bits) x 30 = 18Mbytes/sec 가 됩니다.
정보량이 굉장히 많죠? 이는 압축이 필수 요소라는 것을 알 수 있습니다.
영상처리의 과정에 대해 알아보겠습니다. 여러개가 있지만 RGB-YUV Convert 를 먼저 보겠습니다.
사람의 눈이 색상보다 명암 에 예민한 걸 알고 계시나요? 더 예민하기 때문에 정보량을 조금이라도 줄이기 위해 색상보단 명도에 집중하는게 좋겠죠? 이런 개념을 도입한 게 RGB-YUV Convert 입니다. 여기서 쓰이는게 Subsampling 인데요. 이는 명도(Y)는 유지시키고 색깔정보(U,V)의 정보량을 줄이는 겁니다.
Subsampling 은 Y,U,V의 비율을 다르게 해서 추출하는 방식입니다.
4 : 4 : 4 로 샘플링하는게 정보를 손실하지 않는 비손실 압축입니다.
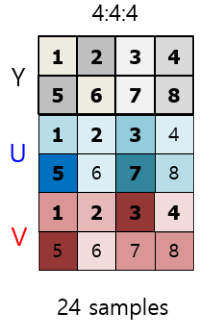
4 : 2 : 2(카메라)
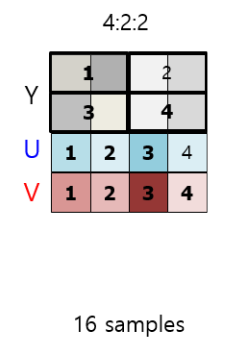
4:2:0(다양한 압축기술) 이경우에는 기존의 4:4:4 보다 50% 압축시킨거라고 하네요.

영상 압축(Video compression)의 방법에는 세가지가 있습니다.
1. 공간적 압축(Spatial Model)
2. 시간적 압축(Temporal Model)
3. 확률적 압축(Entropy Model)
1. 공간적 압축에 대해 알아보겠습니다.
공간에서의 색이나 구조의 변화를 공간주파수(Spatial Frequency)라고 합니다. 주변 구조와 비슷하면 공간주파수가 낮고 크게 변하면 공간주파수가 높다고 할 수 있습니다.

DCT(Discrete Cosine Transform) 은 화소 값 -> 공간주파수인 건데요 이는 한쪽으로 값들이 몰리는 성질인데요. 다음 표를 살펴보면 이해가 가실겁니다. 화소는 주변과 비슷할 가능성이 높습니다. 그 성질을 이용하여 정보값을 줄이기 위해 값을 변환시키는 매트릭스입니다.
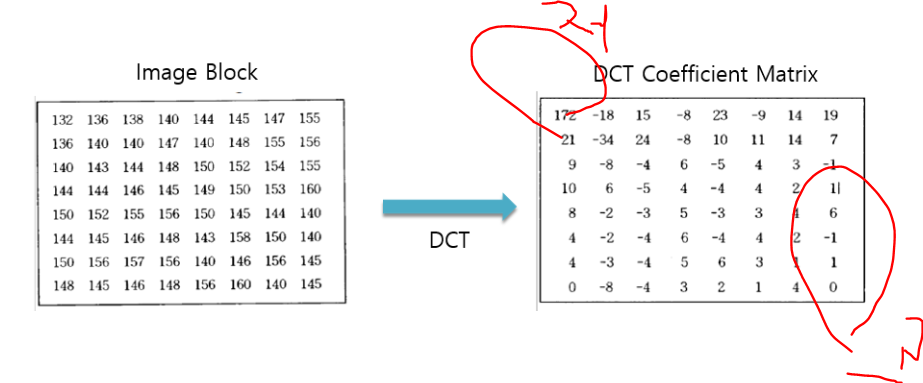
'저 '라고 적힌 위 부분은 저주파 부분입니다. 여기에는 중요한 요소들이 많고 값이 큽니다.
대각선에 고주파영역은 값 차이가 별로 안나고 그다지 중요한 정보가 아닙니다.
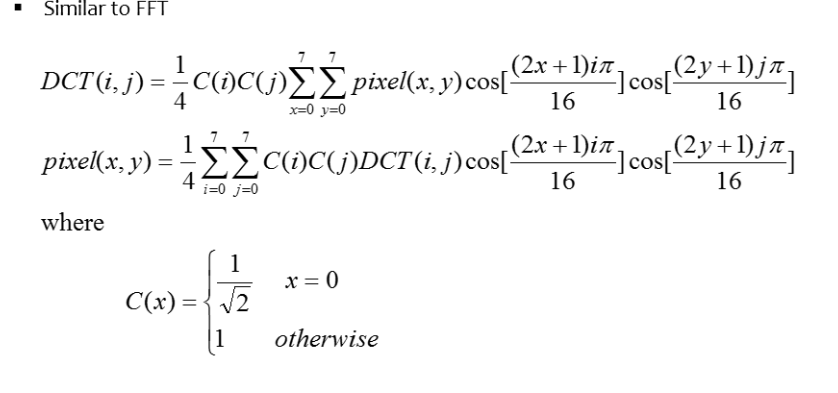
이러한 형식으로 변환을 합니다..(저는 잘 모르겠네요. 수학 시러요.)
즉 이런 식으로 공간모델이 형성됩니다.
이미지 블럭 존재 -> DCT로 Coefficient Matrix로 만듦 -> Quantization(Quantization Table을 통해 DCT Coefficient Matrix와 같은 위치에 있는 걸 빼준다.) -> ZigZag Scanning & RLE
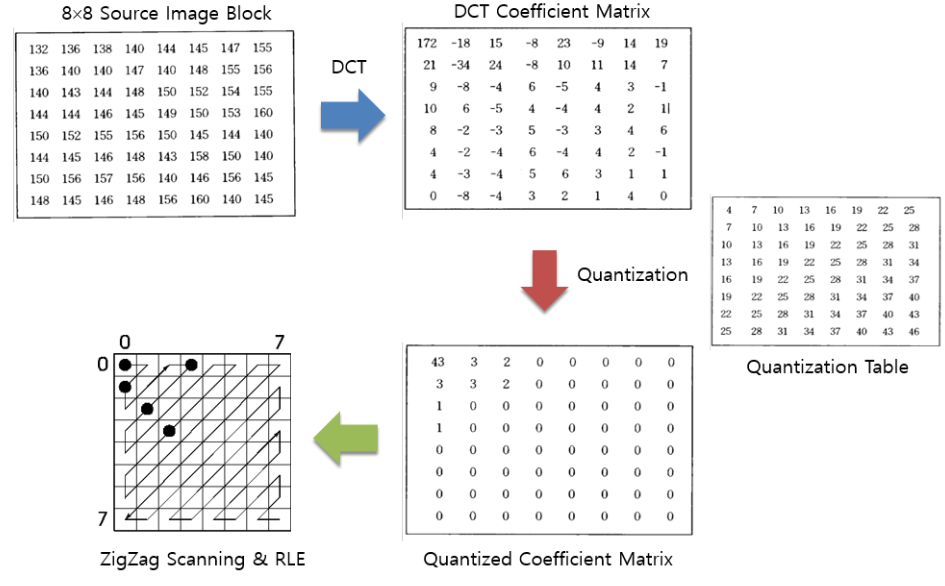
여기서 Quantization 과정을 보면
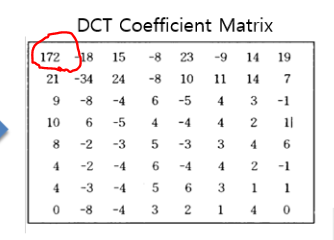
이 테이블과 같은 위치에 있는 값을 나눠줍니다. 그리고 Quantized Coefficient Matrix 에 몫이 저장됩니다.

172/4 = 43 임을 알 수 있죠. Quantization Table 을 보면 왼쪽 윗쪽은 값이 작은 걸 알 수 있습니다. 작은 걸로 할당하면 몫이 많이 남죠. 중요하기 때문에 값을 잘게 쪼개기 위해 작게 부여하는 겁니다. 그와 반대로 오른쪽 아래는 값이 큰 걸 알 수 있죠? DCT Matrix 에 고주파 쪽은 값이 작았으니깐 이렇게 Quantization을 해버리면 왼쪽 아래쪽이 다 0이 되어버리겠죠.
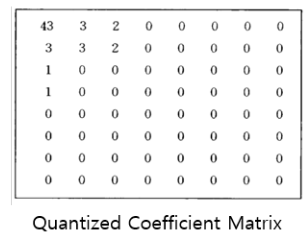
결과적으로 이런 Matrix가 됩니다.
ZigZag Scanning 이란 알고리즘으로 RLE 을 한다고 나와있습니다.
ZigZag Scanning 은 위 표에서 진행과정을 보면 '43 3 3 1 3 2 1 2 0 1 0 0 0 0 0 0 0 0 0' 이러합니다. 이처럼 뒷쪽에 다 0으로 나오게 하는 방식입니다.
그리고 RLE 는 'Run Legnth Encoding' 이라는 의미 인데 수가 나온 횟수 만큼 짝을 지어줍니다.
위 표에서 생각해보면 (43,1) (3, 3) (3,3) (1,2) (0, 많이) 이렇게 나옵니다. 이런 식으로 쓰면 0이 많기 때문에 좀 더 효과적으로 값을 볼 수 있습니다.
이렇게 디지털 포맷팅 하는 방식과 영상처리 등을 배워보았습니다. 수고하셨습니다.
'공부 > 데이터통신' 카테고리의 다른 글
| HW4 리뷰 (0) | 2020.06.15 |
|---|---|
| Formatting and Source Coding(2) (0) | 2020.06.12 |
| 데이터통신-Signal Encoding/Modulation(2) (0) | 2020.06.03 |
| Routing (0) | 2020.05.26 |
| Forwarding vs Routing (0) | 2020.05.21 |



