오늘은 컴퓨터의 Top-Level 구조에 대해 살펴보겠습니다.
현재의 컴퓨터들은 폰 노이만 구조입니다.
폰 노이만 구조의 특성은 세가지가 있습니다.
1. 데이터와 명령어가 RW memory 에 저장
(가장 큰 특성)
2. memory의 주소값에 의해 구분
3. 순차적 실행
반대로 Hardwired program 존재
하드웨어적으로 선이 연결이 되어 있는 프로그램입니다. 이는 쉽게 변경할 수 없습니다.
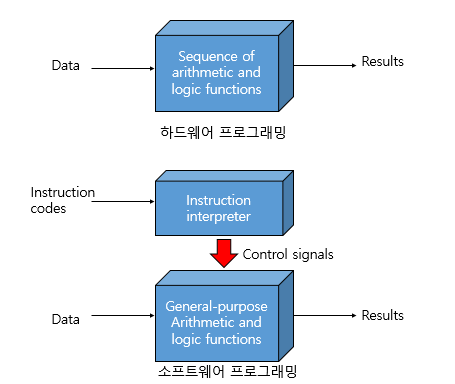
이 로직 함수 박스가 덧셈이라고 생각해봅시다. 그럼 숫자를 넣었을때 덧셈이 되겠죠. 근데 갑자기 나눗셈을 하고 싶습니다. 그러면 하드웨어 프로그래밍에서는 방법이 나눗셈 로직 함수 박스를 다시 들고와서 다시 꽂는 거 밖에 방법이 없습니다. 하지만 소프트웨어 프로그래밍에선 그냥 명령어를 '나눗셈'이라고 넣어주면 됩니다. 그럼 명령어 해석기에서 Control signals로 나눗셈을 하게됩니다. 소프트웨어의 이름처럼 이렇게 유연성이 있는 프로그래밍입니다.
Software
-코드나 명령어의 순서만 바꾸면 어떠한 동작을 실행할 수 있음
-하드웨어의 일부분이 각 명령어를 해석하고 적절한 제어 시그널을 발생시킴(Instruction Interpreter)
-새로운 기능을 수행하는 프로그래밍을 만들려면 새로운 코드를 넣으면 됨. (하드웨어는 선 자체를 재구성해야함)
Major components(I/O Componnents)
-CPU : 명령을 해석하고 범용 산술 연산 모듈을 가짐
-I/O Components(CPU 관점)
- Input module
- Output module
MAR (Memory Address Register)
: 메모리와 CPU 사이에 데이터가 이동할때 이 곳에 저장
MBR (Memory Buffer Register)
: 데이터를 입출력할 때 저장하는 곳
I/OAR (I/O Address Register)
: 어디 디바이스냐, I/O의 주소를 가리킴
I/OBR (I/O Buffer Register)
: CPU와 I/O 디바이스 사이에 데이터가 이동할때 저장하는 곳
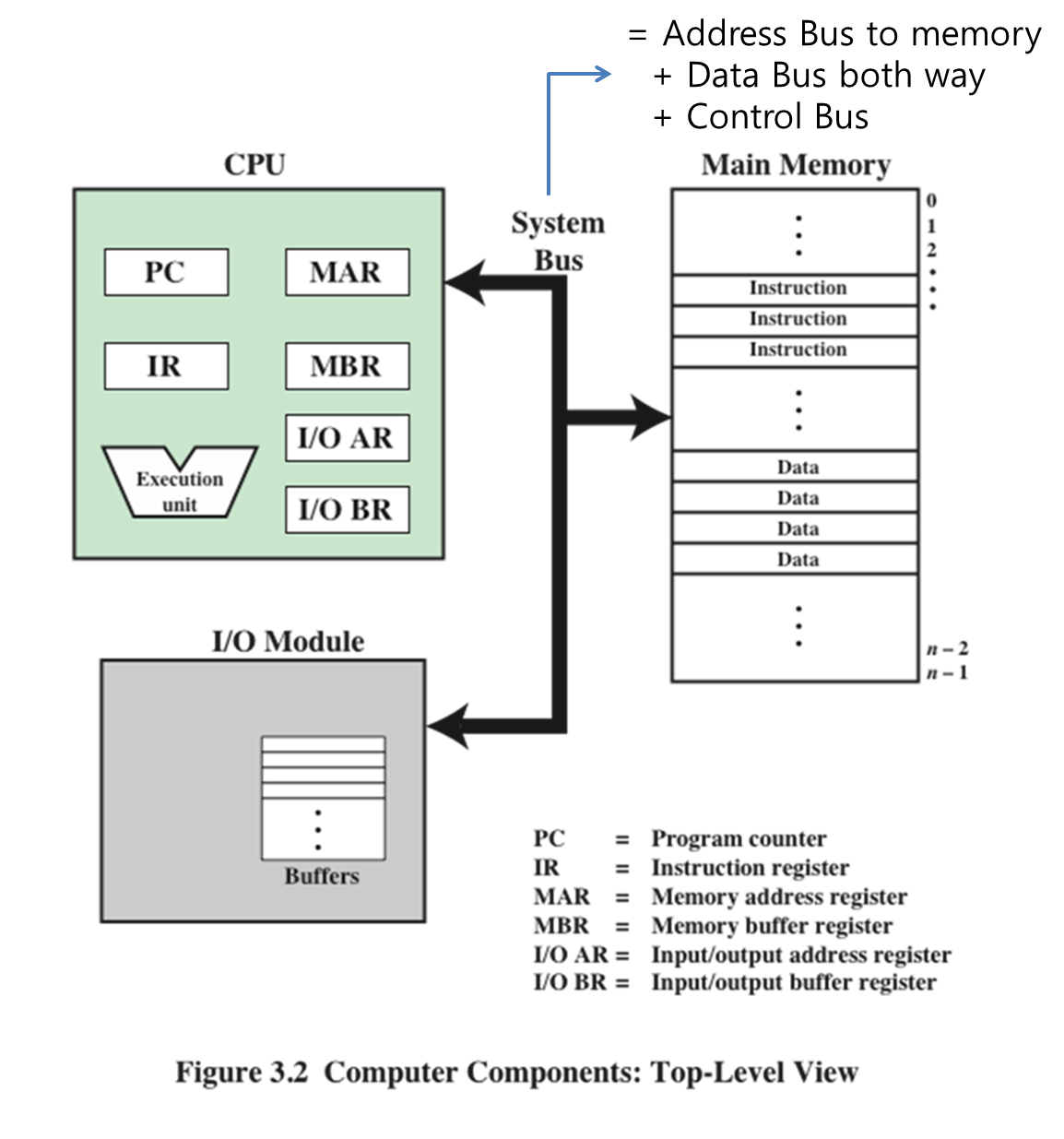
PC 는 다음 실행할 주소를 가지고 있습니다.
IR 는 명령어를 저장하는 레지스터입니다.
MBR 는 출력할 데이터, 메모리로 갈 데이터, 메모리로 올 데이터 등이 저장됩니다.
MAR 는 그 주소들을 가리킵니다.
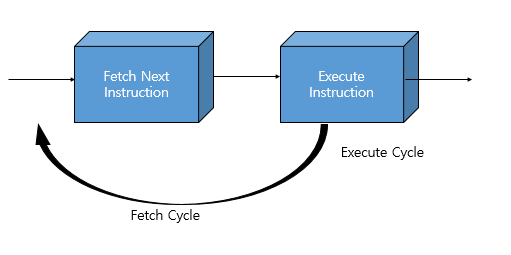
카운터값에 해당되는 주소값에 있는 명령어를 페치해옴. 실행전에 디코딩(해석)을 해서 실행시킵니다.
Fetch 용어
-사전적 정의 : go for and then bring back
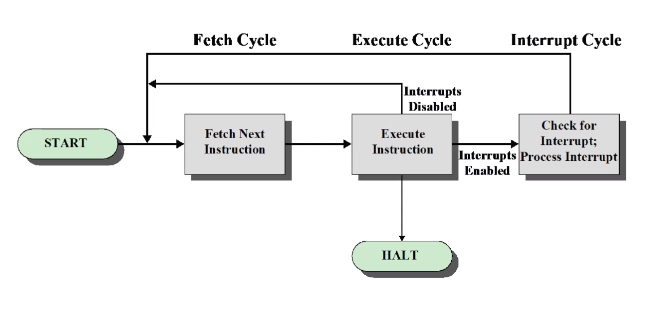
Fetch Cycle
프로세서가 PC가 가지고 있는 주소정보를 줘서 그 메모리로 부터 명령어를 페치해옵니다.
가지고 오고 나면 PC는 자연스럽게 다음 명령어를 가지고 옵니다.
16비트 컴퓨터면 명령어는 16비트 = 2 bytes 입니다.
16비트 컴퓨터가 초기 명령 주소 값이 1 이면 다음 명령 주소 값은 3 입니다.
가져온 명령어는 IR에 저장이 됩니다.
이 명령어는 디코더에 의해 해석이 됩니다.
CPU 에서 일어나는 동작
Processor-memory : 데이터들이 이동함
Processor-I/O : I/O 사이에서 데이터들이 이동
Control : 명령어를 해석해서 나오는 시그널
Data processing : CPU 에 기본 동작, 데이터에 대해서 산술연산이나 쉬프트 앤드같은 로직연산을 수행
프로그램이 실행되는 모습

Opcode 는 쉽게 말하면 동작 코드입니다. 1 + 2 -> 3 을 생각해봅시다. 이때 실행되는 동작코드는 +입니다. 이런식으로 더하기다 빼기다 쉬프트를 한다 로테이션한다 곱셈을 한다 점프를 한다 조건을 체크한다 이런 것들이 다 opcode 입니다. 그리고 1하고 2는 operand 라고 동작 대상입니다.
프로그램 실행 예시
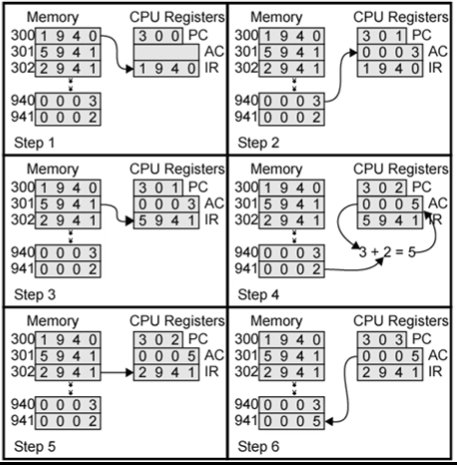
IR(Instruction Register)는 위 그림에서 봤듯이 앞에 4가 opcode 입니다. 그에 따른 명령어는 다음과 같습니다.
0001 : Load AC from memory
0010 : Store AC to memory
0101 : Add to AC from memory
그럼 그림을 보면서 이해해가볼까요? Step1을 봅시다.
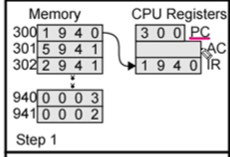
프로그램 카운터가 300 입니다. 그러면 IR 에는 300에 들어있는 데이터가 들어있겠죠? 1 9 4 0 입니다.
그럼 opcode 는 0001 이니 위에서 봤던거 처럼 'Load AC from memory' 라는 의미가 있습니다. 이는 1를 제외한 address '940 를 AC 에 로드해라~' 라는 의미입니다. 940 주소에는 0 0 0 3 값이 들어 있네요.
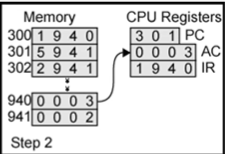
Step2에서 AC(accumulator)에 940 주소에 있는 데이터가 들어가 있음을 볼 수 있습니다. 그리고 PC는 다음에 실행할 주소를 가리킵니다.
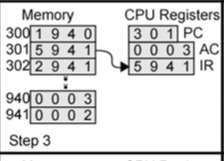
PC에 있는 301 에 명령어를 페치시킵니다. IR 에 5 9 4 1 이 들어왔습니다. 위에서 말했듯이 앞에 4비트는 Opcode 입니다. 5는 'Add to AC from memory ' 라는 거죠. 그럼 941 에 있는 데이터를 AC에 더해라는 겁니다. AC의 값은 어떻게 될까요. 0 0 0 3 + 0 0 0 3 = 0 0 0 5 가됩니다.
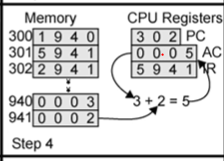
AC에 값이 0 0 0 5가 되었고 PC는 다음에 실행할 Instruction 주소를 가리킵니다.
다음 동작을 예상해볼까요?
302 에 있는 2 9 4 1 이 실행됩니다. 앞 4비트가 2이기 때문에 'Store AC to memory' 이는 AC에 있는 값을 데이터 메모리에 저장해라는 뜻입니다. AC에 있는 값을 941 에 저장합니다. 지금 AC에 값은 5이기 때문에 941 에 0 0 0 5가 들어가게 됩니다.

다음은 이러한 동작들이 어디서 일어나는지에 대해 살펴보겠습니다.
이 그림은 Instruction Cycle State Diagram 입니다.

-
명령어 주소 계산
명령어 해석 디코딩
Operand address 계산
Data Operation(CPU 내에 ALU)
Operand address calculation
->CPU 에서 실행 processor 내부의 동작
명령어 fetch, Operand fetch, Operand store
->Memory 와 CPU Register 사이의 즉 프로세서와 메모리 혹은 프로세서와 I/O 사이에서 동작
Interrupts
운영체제에서 배우는 개념, 컴퓨터 구조 관점에서의 interrupts 들을 알아봅시다.
| Program | 명령어 실행에 결과로 부터 얻어지는 interrupts , 산술 오버플로우, 0에 의한 나눗셈, 메모리 영역을 넘어서 참조 등등 |
| Timer | 프로세서 내부에 타이머에 의해 발생하는 interrupts -> 조건에 따라 특정한 동작을 실행할 수 있게 함. (많이 사용되는 거 : 워치독 - 화성탐사선) 워치독 : 특정 시간동안 동작을 안 할때 리셋을 해버림 |
| I/O | 어떤 동작이 끝났을 때(프린터가 끝났을때 CPU에게 알려줄때) |
| Hardware failure | 가장 우선 순위가 높은 interrupts , 메인 보드등에 문제가 생겼을 때 등등 |
프로그램의 Flow Control 흐름제어에 대해 알아봅겠습니다.
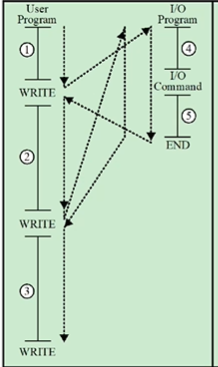
이 경우는 interrupts가 없는 경우 입니다. I/O 디바이스를 프린터라고 가정할때 1의 연산, 덧셈이라고 가정하고 덧셈이 실행되고 그 결과를 프린트하는데 프린트가 끝날때까지 기다리고 난 후 두번째 연산을 진행하는 겁니다.
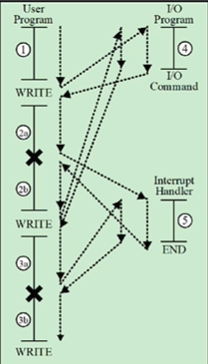
이 상황은 interrupts가 존재하는 데 I/O Wait가 짧은 상황입니다. 첫번째 연산인 덧셈을 실행하고 프린터를 맡기고 두번째 연산을 실행하는 도중에 프린터가 다 됐다고 인터럽트가 오는 상황인겁니다. 이때 Interrupt Handler 프로그램으로 '그래 너 다 됐어?' 라고 확인을 하고 다시 두번째 연산을 진행합니다. 그리고 이 내용을 다시 프린터하고 세번째 연산 진행하는 와중에 인터럽트 받고 Interrupt Handler 로 확인하고 세번째 연산을 마저 진행합니다.
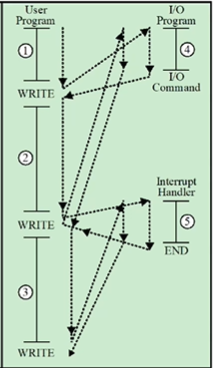
다음은 인터럽트가 존재를 하지만 긴 I/O Wait가 있는 상황입니다. 즉 프린터를 맡기고 두번째 연산이 끝날때까지 인터럽트가 오지 않는겁니다. 이러면 두번째 연산이 끝나고 이에 관한 결과도 프린트를 해야하기 때문에 어쩔 수 없이 Wait를 하게됩니다. ( 사실 요즘에는 다 보내기도 하지만 이 상황에서 고려하지 않습니다.) 첫번째 연산에 대한 프린트가 끝나고 인터럽트 핸들러로 확인하고 나서야 두번째 연산을 프린터 보냅니다. 이 때도 세번째 연산이 끝날때까지 인터럽트가 돌아오지 않아서 Wait 하는 상황이 발생합니다.
인터럽트를 통한 Flow Control 변화
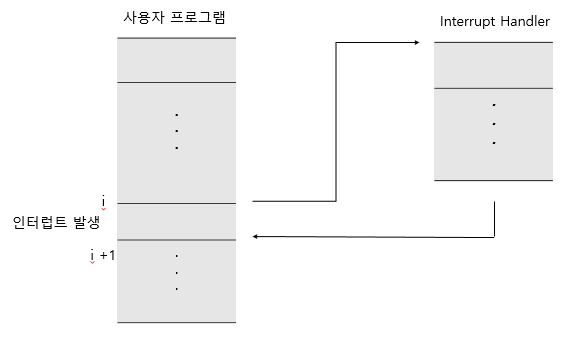
인터럽트가 발생이 되면 프로그램의 진행 순서가 변화가 됩니다. 여기선 i 번째 명령까지 실행이되고 인터럽트가 발생이 됩니다. 이 시점에서 PC는 i + 1 주소값을 가지고 있었을 겁니다. 인터럽트가 발생이 되면 PC의 주소는 Interrupt Handler 주소를 가지게 됩니다. 핸들러가 끝나면 PC 는 다시 i + 1 의 명령어 주소를 가지게 될 겁니다.
Interrupt -> Interrupt Handler -> User Program Resume
여기서 사용자 프로그램은 특별한 기능을 안하고 운영체제와 프로세서가 알아서 다 해줍니다.
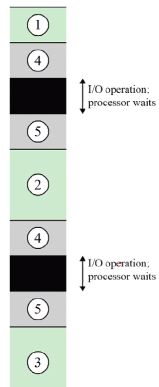
CPU 의 사용률 효율성에 대해 보겠습니다. 검은색 부분은 CPU가 어떤 행동도 안하고 기다리고 있는 중입니다.
여기서 검은색은 I/O 작업 중에 아무 것도 안 하고 기다리고 있는 상황입니다. 4 는 장치 사용 전 작업이고 5는 장치 사용 후 작업입니다. 인터럽트 개념을 도입하고 난 후를 보겠습니다.
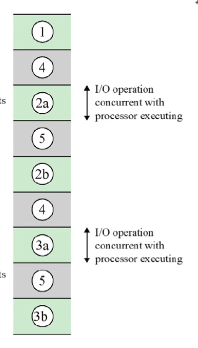
딱 봐도 검은색 부분이 사라진 걸 알 수 있습니다. 프린트를 시키고 두번째 작업을 하고 인터럽트를 받으면 장치사용 후 작업을 마친 후 다시 돌아와서 두번째 작업을 마무리합니다. 딱봐도 인터럽트를 통해서 Flow가 효율적인 것을 알 수 있죠.
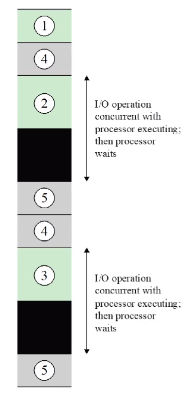
위에서 봤듯이 긴 I/O wait 를 가진 건 첫번째의 프린트 작업이 끝나기 전에 두번째 작업이 끝나기 때문에 기다리게 됩니다. (동시에 프린트를 돌릴 수가 없기 때문입니다.) 첫번째 프린트가 끝나고 장치 작업 후 처리 5를 끝내고 두번째 작업의 프린트를 사전 준비를 합니다.
이처럼 multiple interrupts 를 처리할 수 없다면 CPU가 멈추는 검은색 부분이 생길 수 밖에 없다는 것을 알 수 있습니다.
Instruction Cycle State Diagram With Interrupts
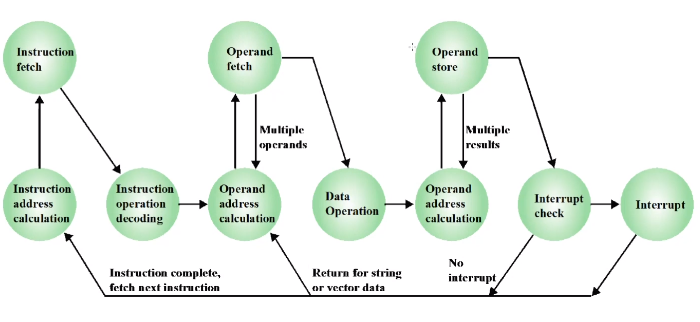
윗 줄에 Instruction fetch, Operand fetch, Operand store 는 프로세스하고 메모리 사이에 일어나는 CPU 외부에서 일어나는 작업이라 생각하면 되고 아랫줄은 CPU 내부에서 작동되는 거라고 생각하면 됩니다.
위에서 본 사이클과의 차이는 Interrupt를 check 하고 해결하는 부분이 추가되었습니다.
Multiple Interrupts 대처방법
1) Sequential Interrupt Processing
X,Y 인터럽트 발생 -> 동시 처리 아님 -> X 처리 끝나고 사용자 프로그램에 돌아오고 -> Y처리
2) Nested Interrupt Processing
X 인터럽트 발생 -> X 처리 도중 Y 발생 -> Y처리 -> 처리 후 X 처리 마무리 -> 사용자 프로그램으로 돌아옴
지금까지 CPU의 기본적인 동작 메커니즘을 봤고 중요한 인터럽트 개념을 보면서 CPU의 Cycle 상태 다이어그램과 연결 시켜서 봤습니다.
이제는 CPU Memory 입출력, 입출력을 한번 보도록 하겠습니다.
I/O Function
- I/O module : 프로세서하고 직접적으로 데이터를 교환, 실질적인 입출력 디바이스가 아니라 입출력 디바이스와 CPU의 매개체 역할
- Processor 는 I/O module 하고만 입출력 통신을 함
- Memory 와 I/O module 사이에 통신 : I/O module 과 Processor가 통신 Processor와 Memory 가 통신. 이게 기본적인 상황. 하지만 특별한 케이스 존재 I/O 가 메모리에 직접 통신을 할때 좋은 상황이 존재.(DMA - Direct Memory Access)
원래 메모리와 입출력에 접근하는 가장 중요한 건 프로세서입니다. 통신이 늘 프로세서를 거쳐서 진행되었습니다. 하지만 DMA 는 직접적으로 입출력 모듈이 메모리에 데이터를 쓰거나 데이터를 읽어오는겁니다.
Computer Modules
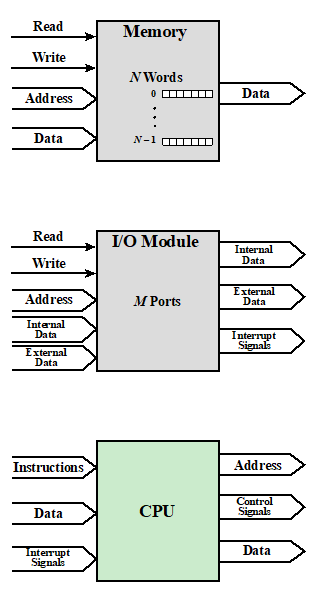
메모리에 데이터를 쓰고 읽기 위해 Read , write Control Signal 이 필요합니다. 어디에 써야하는지 알아야하니 Address 와 Data도 필요합니다.
I/O Module 도 외부로 부터 데이터를 읽고 쓰는 Control Signal 필요합니다. 여러 I/O device 와 여러 I/O module이 있기 때문에 Address 도 필요합니다. CPU,memory 로부터 오는 게 Internal Data 외부로 부터 오는게 External Data 입니다. 그리고 중요한 부분이 Interrupt Signals 을 발생시킨다는 겁니다.
CPU 가 Interrupt Signals을 받습니다. CPU는 당연히 코드, 즉 명령어를 받아드려서 해석하고 Control Signals 을 발생시킵니다. 그리고 Data 를 받아드려서 Data를 내보냅니다. 그리고 CPU가 Address 를 보냅니다. 이 Address는 Memory 나 I/O Module로 보내는 걸 알 수 있습니다. (어디에 있는 데이터를 어디에 옮긴다던지 혹은 어디에 데이터를 쓴다든지 할때 발생)
이 중 대장은 CPU 입니다.
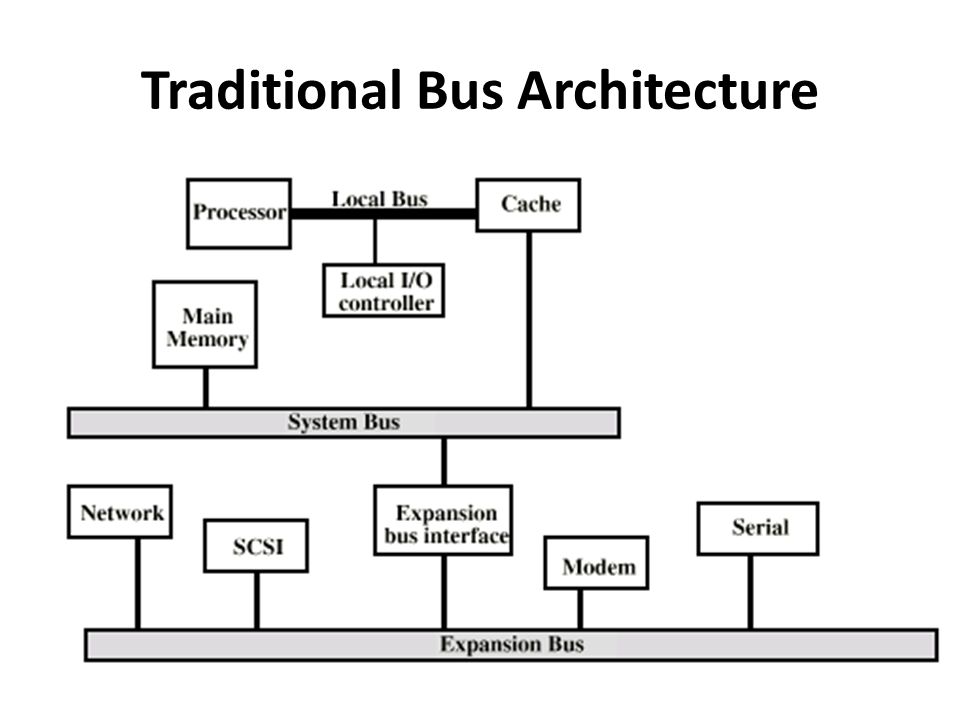
Processor 와 Cache 아주 빠른 버스 Local Bus
Processor 와 Memory 사이의 버스 System Bus
Network, SCSI, Modem, Serial 아주 느린 버스 Expansion Bus
이러한 계층 구조입니다.
Data Bus
데이터를 전송하는 버스
32, 64, 128 데이터버스
32 데이터 버스라고 하면 한번에 32비트를 병렬적으로 전송할 수 있는 버스입니다. (한 클럭에 처리할 수 있는 수)
데이터 버스의 width가 프로그램 성능에 있어서 굉장히 중요한 부분입니다.
Address Bus와 control 버스가 있습니다.

CPU와 Memory 그리고 I/O 가 버스를 공유하는 초기의 형태입니다. 앞에서 본 전통적 계층구조와는 좀 다르다고 할 수 있습니다. 여기선 빠른 디바이스나 느린 디바이스 구별 없이 사용 하고 있습니다.
SCSI, Network 은 고속 I/O 디바이스입니다. Modem 과 Serial 은 저속 I/O 디바이스입니다. 그럼으로 밑에 그림처럼 빠른 속도의 버스를 사용하게 됩니다. 이렇게 하면 전체적인 성능이 더 높아지게 됩니다.

Bus Design Elements
Type : Dedicated, Multiplexed
Method of Arbitration : Centralized, Distributed
Timing : Synchronous, Asynchronous
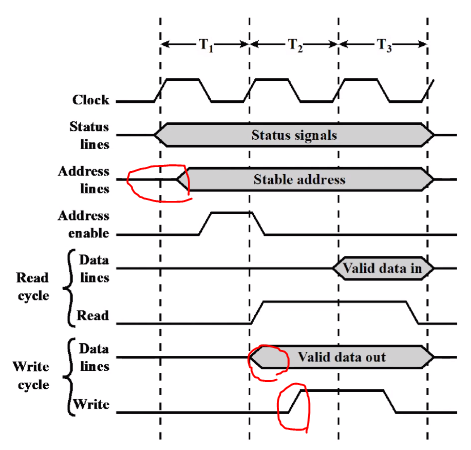
Timing of Synchronous Bus Operations
Synchronous 란 동기화입니다. 동기화를 할려면 기준이 있어야합니다. 이 기준은 Clock 입니다. 변화를 보면 clock의 rising에 맞춰져 있는걸 볼 수 있습니다. Address lines은 Delay가 되어 있고 Address enable은 falling에 맞춰져 있어보입니다. 어쨌든 중요한 건 clock 기준이라는 겁니다.

//Address enable : 주소가 유효한지
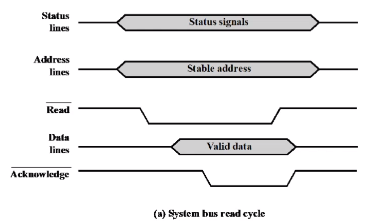
Read cycle은 프로세서가 메모리의 특정 위치 값을 읽는 사이클입니다. 특정 위치니깐 Address 가 필요합니다. 프로세서가 Address를 Generate 합니다. 16비트,32비트 라고 하면 안정화하는데 약간의 시간이 걸렸습니다. 반클럭 이후에 주소값을 받았다는 걸 보고 enable 합니다. 메모리 입장에서는 다음 클럭 라이징에서 해당되는 어드레스 값을 활용할 수 있게 됩니다. 그래서 memory 에서 Read Control Signal을 보내게 됩니다. 그럼 메모리 하드웨이 입장에서는 Address enable 를 받고 Stable address가 존재하고 Read Control Signal을 받았으니 그에 대한 데이터를 출력을 내야합니다. 그게 Vaild data in입니다. 메모리 입장에서는 데이터 출력이지만 CPU 입장이기 때문에 버스에 실린게 있으니깐 Data in 이라고 표현을 했습니다.

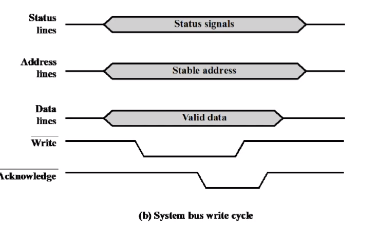
write 하는 상황을 보겠습니다. 특정 메모리에 써야하니 Data 가 필요하고 Address 가 필요합니다. 그리고 쓰게 다는 Write Control Signal 을 CPU 에서 발생시켜서 Memory 에 넣어주어야합니다. 특정 주소에 써야하기 때문에 첫 클럭에서 Address를 발생시켰습니다. 그리고 주소에 쓸 데이터를 두번째 클럭에서 출력을 했습니다. 그리고 두번째 falling 에서 write signal 을 보냈습니다. 메모리가 이걸 받고 어느 주소에 쓸건지 Address와 Data 를 받으면 됩니다.
Timing of Asynchronous Bus Operations
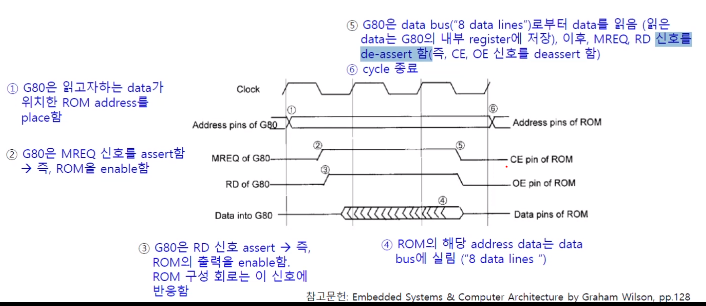
비동기식 버스의 동작을 살펴보겠습니다. 비동기식은 어떤 한 시그널의 결과에 의해서 두번째 시그널의 동작이 결정되는 겁니다.

G80 라는 프로세서가 Rom을 Read 합니다.
Address 는 프로세서가 생성을 합니다. 이 Address 를 Rom 을 받아서 Data 를 출력합니다.
MREQ (Memory Request) 신호, RD(Read) 신호 : 네거티브 로직 (0으로 떨어졌을 때가 active)
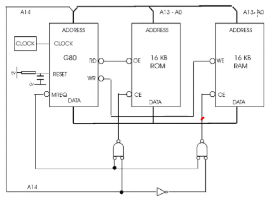
RAM 에 Data를 Wirte 하는 cycle
address 라인이 A14라인이 빠져나와서 프로세스에 메모리 리퀘스트 와 and 되어서 RAM 에 데이터를 enable 시킵니다. 그러면 A14가 1이 되어야만 access가 가능한 상태입니다. RAM address 공간은 0x4000 ~ 7FFF사이입니다. 즉 0100 000 0000 0000 ~ 0111 1111 1111 1111 이에 A14는 1이 되어야하는 address 공간입니다.
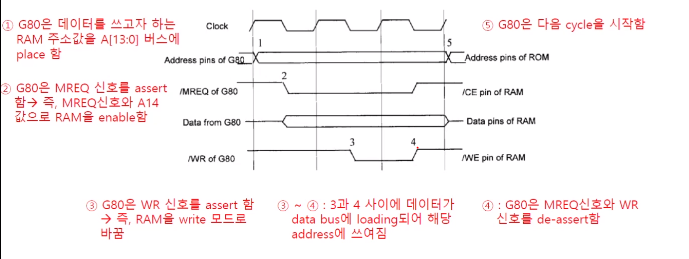
실제 주소를 A13 : A0 까지에 의해서 지정됩니다. 해당 주소를 버스에 쓸고 칩을 enable하는 메모리 리퀘스트를 띄웁니다. 그리고 쓸 데이터를 로딩하고 쓰는 시그널을 보냅니다.
Point-to-Point Interconnect
요새는 공유되는 버스가 아니라 특별한 버스를 사용합니다. 버스를 공유를 공유하게 되면 Control Signal에 간섭에 의해 Delay나 왜곡이 더 많이 생깁니다. 그래서 요새는 패킷 등과 같이 사용하게 됩니다.
Quick Path Interconnect
-Multiple direct connections
-Layered protocol architecture
-Packetized data transfer
통신에서 사용하듯이 계층 프로토콜을 사용합니다.
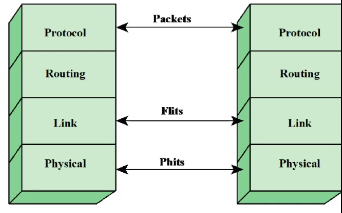
PCI Protocol Layers 거의 동일
이렇게 Chapter 3. A Top-Level View of Computer Function and Interconnection 이 끝났습니다.
-Computer components
-Computer function
1) Instruction fetch and execute
2) Interrupts
3) I/O function
-Interconnection structures
-Bus interconnection
1) Bus structure
2) Multiple bus hierarchiese
3) Elements of bus design
이렇게 배워봤습니다. 수고하셨습니다.
'공부 > 컴퓨터 구조' 카테고리의 다른 글
| 컴퓨터구조5 Internal Memory (0) | 2020.06.12 |
|---|---|
| 컴퓨터구조4 Cache Memory (0) | 2020.06.05 |
| 컴퓨터구조2 Process (0) | 2020.05.27 |
| 컴퓨터 구조1 개요 (0) | 2020.05.26 |
| Arithmetic & Logic Unit (0) | 2020.05.25 |



