저번 시간에는 데드락에 대해 배워보았습니다.
https://com24everyday.tistory.com/206?category=1114126
운영체제7 Deadlock
안녕하세요. 옆집 컴공생입니다. 오늘은 Deadlock 에 대해 배워 볼거에요. 저번 시간에는 하드웨어와 소프트웨어의 프로세스 동기화에 배워보았습니다. https://com24everyday.tistory.com/205 운영체제6 Proce
com24everyday.tistory.com
이제 Memory Mangement 에 관해 배워보겠습니다.
- Background
- Swapping
- Contiguous Memory Allocation
- Segmentation
- Paging
- Structure of the Page Table
Background
우리가 이미 알고있는 프로그램이 CPU 에 로딩이 되면 프로세스입니다.
그리고 메모리 하면 CPU 에 있는 레지스터와 메인메모리가 있죠.
CPU 내부에 레지스터는 완전 빠른 저장소입니다.
Main memory 에 들어갈 때는 매우 많은 시간 즉 cycle 을 사용하게 됩니다.
logical memory 주소 공간은 base 하고 limit register 로 정의가 되있습니다.

그림을 보면 중간의 process는 300040 에서 420940 까지 이어집니다. 이 시작점은 base 에 있고 크기는 limit 값에 있습니다.

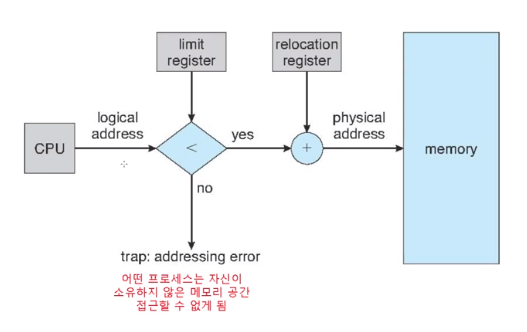
base에 주소 시작이니깐 이보다 크면 진행이 안되고 여기에 limit 을 벗어나면 실행이 안되게 만듭니다.
이렇게 Hardware Address Protection 하게 됩니다.
Address가 어떤 유형으로 존재를 하는지에 대해 소스코드와 컴파일된 코드 링커와 로더로 어떻게 존재하는지 알아보겠습니다.
- Sourece code에서 주소는 당연히 숫자가 아닌 symbol 형태로 표시가 됩니다. (ex : 변수 counter)
- Compiled code 에서는 relocatable addresses로 bind 됩니다. 상대주소에 대한 기준점이 정의가 되면은 실제주소가 정의될 수 있도록 relocatable 주소를 binding 시킵니다. (ex : "14 bytes from beginning of this moddle"
- Linker or loader 는 relocatable 주소(재배치 가능 주소)를 absolute address(절대주소) 로 바인딩합니다. (ex : 74014)
그리고 하드디스크상의 프로그램이 memory에 로딩되기 전에 input queue 에서 대기를 합니다. (Long term Scheduling 대기)
그리고 물리적 주소는 0000부터 시작하지 않습니다.
Address binding
- Compile time address binding : 컴파일 시점에서는 relocatable address 이기 때문에 실제로 물리적 주소를 알지 못합니다. 아는 특별한 경우가 있는데 이는 COM 양식 프로그램이 있습니다.
- Link time binding : 동적 vs 정적 라이브러리
- Load time binding : 컴파일러는 재배치 가능코드를 만들어졌습니다. 그래서 실제 로딩이 될때 symbol 및 진짜 주소와의 바인딩이 이루어집니다.
- Execution time binding : 만약 프로세스가 실행되는 중간에 메모리 내의 한 세그먼트가 다른 세그먼트로 옮겨질 수 있는 경우 '바인딩이 실행시간에 이루어진다; 라고 합니다. 이걸 진행하기 위해서는 특별한 하드웨어가 있어야합니다.

Logical vs Physical Address Space
:이는 메모리 관리를 위한 가장 중요한 개념입니다.
Logical address - CPU 에 의해 만들어짐, 가상 주소
Physical adderess - Memory unit 에 의해 사용
실제로 실행 될때는 Logical address에 어떤 base 가 가해져서 사용을 하게 됩니다.
이처럼 virtual 주소로 부터 physical 주소로 변환을 시켜주는 것이
Memory-Management Unit(MMU) 입니다.

가상 주소 + relocation register value(address) -> physical address
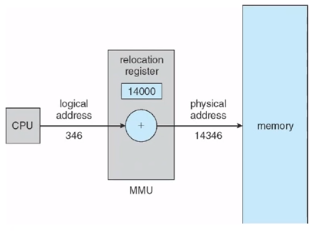
몇가지 개념에 대해 더 알아보겠습니다.
Dynamic Loading

하드디스크에 있는 프로그램들이 memory 로 loading 이 되는 것입니다. 코드 사이즈가 큰 경우일때 유용합니다.
Dynamic Linking 에 대해 배워보겠습니다.
반대로 Static linking 도 있겠죠. 이건 loader 에 의해서 program image 로 통합이 되어 있는 겁니다.
Dynamic linking , 이 linking 이 실행되기 전까지는 되지 않습니다 .

여기서 다음과 같이 서로서로 사용이 되어지게 연결되는 것을 Dynamic linking 이라고 합니다. stub 가 존재해서 linking 을 할 수 있습니다 .

Swapping
: main memory 를 backing store 즉 하드디스크로 보내는 겁니다.
backing store - fast disk large, 용량이 큰 하드디스크
메인 메모리의 용량이 아주 크면 할 필요 없습니다.
작으면 사용할 하면 됩니다.
즉 기본적으로 sapping 을 사용하지 않다가 메모리 사용량이 어떤 기준 이상이 되면 swapping 사용하게 됩니다.

말했듯이 swapping 에서 가장 중요한 것은 Transfer time 입니다.
예를 들어 100MB process 가 있다고 가정해봅시다.
이때 hard disk transfer rate 는 50MB/sec 입니다.
그럼 Swap out time 은 2초입니다. 다시 Swap in 이 되면 2초
최소 4초가 들어가는 겁니다.
즉 이런 context switching 을 줄이기 위해 현재 메모리가 얼마나 사용되어지고 있는지를 정확하게 알아야합니다.
어떤 프로세스를 swap out 하기 위해서는 그 프로세스가 완전히 휴지 상태에 있어야합니다.
만약 이 프로세스가 I/O 장치를 실행을 하고 있다면 어떻게 될까요?
외부로 부터 온 건 처리가 되지 않습니다.
입출력에 관련된 내용이 I/O에서 kernel sapce(buffe)에 저장이 되었다가 buffer 안에 옮겨줍니다.
즉 double buffer 입니다.
flash memory 는 swap in out 을 잘하지 못합니다.
왜냐면 어느 정도 쓰면 데이터 누수가 일어나기 때문입니다.
Contiguous Allocation
그럼 새로운 개념에 대해 배워보겠습니다.
프로세스가 메인메모리로 할당되는 방법입니다.
여기서부터 memory allocation(연속메모리할당)입니다.
즉 각 프로세스는 다음 프로세스를 포함하는 메모리영역과 연속된 하나의 메모리 처럼 보인다는 겁니다.
그리고 알다시피 메인 메모리는 user 과 관련된 부분과 OS 와 관련된 부분이 있습니다.
이 중에서도 OS 관련된 부분의 0번지에는 interrupt vector 가 존재를 합니다.
Relocation Registers(재배치 레지스터) 가 user process 를 protect 하는데 사용이 될 수 있습니다.
Base , Limit 레지스터를 적절히 사용해서 범위를 측정을 하는거죠.
프로그램을 메인메모리에 로딩이 될때 Fixed-sized 와 Variable-sized Partition 이 있습니다.
Fixed-sized Partition 은 OS 에 프로세스가 들어갈 크기가 고정이 되어 있는 겁니다. 만약 이보다 크기가 크면?
받아드릴 수가 없는겁니다.

그래서 나온게 Variable-sized Partition 입니다.

어떤 프로세스가 종료되면 Hole 즉 가용메모리공간이 만들어집니다. 그리고 process를 할당을 해줍니다.
이렇게 동적으로 메모리를 할당을 할 수 있습니다.
- First-fit : 첫번째 사용 가능한 가용 공간에 할당, 검색 대상 시작 혹은 지난번 검색 끝났던 곳에서 시작, 즉 찾다가 들어갈 위치를 찾으면 바로 넣는다는 의미입니다.
- Best-fit : 사용 가능한 공간중 프로세스의 크기를 만족시키면서 가장 작은 공간 선택
- Worst-fit : 가장 큰 공간 선택
이런 할당과 해제를 계속 하다보면 Fragmentation 이 생기게 됩니다.
Fragment 는 메모리 공간 중 일부 사용하지 못하는 메모리 공간을 의미합니다.
여기도 두가지 방식이 생기는데
External Fragmentation 입니다.

이 상황 그대로 에서는 Process 3 을 할당할 수 없습니다. Procees 2 을 Process 1 쪽으로 밀어서 녹색 공간을 늘리면 Process 3 이 이용이 가능합니다. 이를 Compaction 기술입니다.
그리고 Paging 기법도 있는데 이는 메모리도 일정한 크기로 나누고 할당할 프로세스도 일정한 크기로 나눠서 넣어주는 겁니다. 이는 Not Contiguous Allocation 이 되겠습니다.
Internal Fragmentation(내부 단편화) 도 있습니다.
이는 필요한 메모리 공간보다 더 많은 메모리가 할당이 되는 겁니다.
이때 un-used 되는 메모리 공간이 생기는 것을 "내부 단편화" 라고 합니다.

Partition 마다 덜 사용하고 있는 부분들이 있습니다.
Segmentation
: 사용자의 입장에서 메모리를 바라본것



Program에서 사용하는 address는 segment 이름과 안의 offset 값 모두 명시합니다.

Segment는 table 이 존재를 해서 Segment-table base register(STBR) 과 Segment-table length register (STLR) 가 존재합니다.
그림을 보면서 이야기 하겠습니다.

CPU 가 가상 주소를 발생을 시킵니다. 이 가상 주소의 앞 부분에는 몇번째 세그먼트냐 하는 Segment 번호가 존재를 합니다.

이 번호를 따라서 쭉 가보면 limit(size)과 base(시작주소)가 있습니다.

근데 이게 크기를 벗어나면 'Trap : addressing error' 가 발생을 한 것 입니다.

안 발생하면 정상이구나 해서 d 변위값이 base 값과 더해져서 물리적인 주소가 됩니다.



Segmentation은 사이즈가 다양하고 Compiler 가 이게 어떤 segment 로 들어갈지 결정을 하게 됩니다.
Paging
Paging 에 대해 알아보겠습니다.
프로세스가 메인메모리에 할당될 때는 Continuous 하게 이루어지는 경우가 많지는 않을겁니다.
그래서 external fragmentation을 최대한 줄이고 싶다. 그리고 사이즈를 다양하게 해서 메모리를 효율적으로 사용하고 싶다 라는 생각해서 나온게 Paging 기법입니다.
Physical memory 를 divide 한 것을 Frames
Logical memory를 divide 한 것을 Pages 라고 합니다.
이 두 공간을 연결 시켜주는 것을 page table 이라고 합니다.
그림을 보면서 설명해 드리겠습니다.

CPU 에서는 logical 한 주소 공간을 만들어냅니다. 앞에 P가 있습니다. 이는 Page 주소 입니다.
d는 page 내에서의 offset 입니다. 즉 p로 frame 주소를 찾습니다. 이게 page table 입니다.
Page number (p)
Pae offset (d)

page table 은 메인메모리에 있습니다. 이는 속도가 느립니다. 그래서 나온게 TLB(Tanslation Lookaside Buffers) 가 있습니다. 마치 캐시같은 존재인거죠. Page Number 을 TLB 에서 병렬 비교로 Frame 을 찾아냅니다. 또 associate memory 로 Context Addressing(내용으로 찾아냄) 을 한다고 합니다 .


Page table 이 메인메모리에 있어서 속도가 느리기 때문에 TLB를 쓰다는 것을 이해를 해야합니다.

Page Table 은 이렇게 찾아주는 거 외에도 Memory Protection 기능도 제공을 합니다.
valid - invaild
페이지 넘버 2는 frame 4 로 할당이 되어있습니다. 그래서 접근을 할 수 있다는 겁니다.
그리고 address 0 에 access 할 수 있는 건 없습니다.

Shared Pages 개념에 대해 배워 보겠습니다.

그림을 보면 이해가 됩니다. 세 개의 프로세스가 있고 이는 모두 각각의 Page table 을 갖게 됩니다.
프로세스의 코드 모양을 보면 ed는 동일하고 data 는 다 다른 걸 가지고 있습니다.
이러면 실제 세개의 프로세스는 동일한 physical memory 에 참조를 해야합니다. ed1 은 frame number 3 라고 되어 있습니다. 세개의 프로세스가 sharing 을 하고 있는 겁니다. data 들은 각자가 가지고 있기 때문에 sharing 이 안되어 있는 겁니다.
Shared code
- Read-only (Reentrant)
- 함수형 코드가 이런 경우가 많은
Private code and data
Reentrant code 란 함수형 언어의 대표적 특성으로 동시에 접근해도 언제나 같은 실행결과를 보장해야합니다. 이를 위해 전역/정적 변수를 사용하면 안됩니다. 항상 호출자가 호출시 제공한 parameter 만으로 동작해야합니다.
Page Table 의 구조
- 32-bit logical address
- Page size of 4 KB(2^12)
- Page Table ( <- 2^32 / 2^ 12) = 2^20 = 1 million
- 하나의 entry is 4 bytes -> 4MB ( 4B * 2^20)
그래서 메모리의 양이 큽니다.
이제 다음 Page Tables 에 대해 알아보겠습니다.
-
Hierarchical Paging
-
Hashed Page Tables
-
Inverted Page Tables
-
Hierarchical Paging
- 페이지가 계층적으로 구성이 되어 있는 겁니다.

Two-Level Paging Table 은 다음과 같이 주소가 구성이 되어 있습니다.


- Hashed Page Tables
- 또다른 중요한 개념입니다. 이는 address spaces 가 32 bit 보다 커지면 거의 이 기법을 사용합니다.
- 즉 주소 공간이 32 bit 보다 커지면 가상 주소를 해쉬화해서 사용하는 해쉬 페이지 테이블을 많이 사용하는 겁니다 .

그전에는 바로 P 로 바로 table 에서 값을 찾았습니다.
하지만 여기서는 hash function으로 hash 값을 얻어서 Hash table 에서 요소를 찾는 겁니다.


next element 가 왜 생기냐면 hash function 에서 충돌이 일어나기 때문입니다. 다른 값이 들어가서 동일한 해쉬값을 가질 수 있는겁니다. 그럼 같은 슬롯을 쓰게 되는데 그러면 안되니깐 있는겁니다. q와 비교해서 다르면 '아 다른 걸 찾아야 겠구나 하고 다음 element 에 가는 겁니다. p가 맞구나 하고 그럼 여기 frame 값 뭐냐 해서 r이다. 하면 이걸 frame 값으로 해서 offset 을 더해서 Physical memory 값을 찾습니다.
- Inverted Page Table
기존 Page Table 의 문제점
프로세스가 여러개입니다. 이게 다 로딩 되는데 이들이 다 Page Table 을 각각 가지니 메모리 소비가 많습니다. 또 multilevel Page Table 을 사용하면 메모리 사용이 더 크겠죠.

프로세스가 2GB인데 Page Table Size 만 16Mbyte 입니다.
이러한 문제해결을 위해 Inverted Page Table 기법이 나왔습니다.
이는 physical 메모리 하나당 페이지 테이블이 하나밖에 없다는 겁니다. 프로세스마다 있는게 아닌거죠. 오버헤드를 왕창 줄일 수 있습니다.



이게 가리키는 i는 physical memory 의 frame 번호가 됩니다 .
여기서 만약 못 찾으면 어떻게 되나. 그럼 그 값이 메인 메모리에 없다는 의미로 Segmentation Fault 가 발생이 되게 됩니다.
장점
- Memory space reduced
단점
- Longer lookup time : 찾는데 너무 오래 걸림, 더 빠른 검색 방법이 존재 그래도 단점
- Difficult shared memory implementation : 공유 메모리 구현이 어렵습니다. 단일 싱글 엔트리를 각 frame 마다 가지고 있기 때문에 chaining 기술을 써서 표현해야함. virtual address 를 각 frame number 로 맵핑시켜야 합니다.

Inverted Page Table 에 page table 은 Main memory 에 frame 으로 인덱싱되어 있습니다. 그러면 해당되는 id 는 빠른 비교로 찾을 수 밖에 없습니다.
다른 page table 은 page 로 인덱싱이 되어 있기 때문에 찾기가 좀 쉽습니다.
하지만 메모리의 소비 차이가 있다는 거.
OS 가 난이도가 높습니다.
컴퓨터구조와 운영체제를 계속 함께 보면서 공부를 해야합니다.
'공부 > 운영체제' 카테고리의 다른 글
| [윈도우] 레지스트리란 (0) | 2021.05.11 |
|---|---|
| 운영체제7 Deadlock (0) | 2020.07.03 |
| 운영체제6 Process Synchronizaiton (0) | 2020.07.03 |
| 운영체제5 CPU Scheduling (0) | 2020.06.21 |
| 운영체제4 Threads (0) | 2020.06.17 |



