안녕하세요. 이번 챕터 5에서는 CPU Scheduling 에 대해 배워 볼거예요.
아래는 그전 포스팅 'Threads' 이니깐 참고해주세요ㅎㅎ
https://com24everyday.tistory.com/161?category=1114126
운영체제4 Threads
이번 단원에서는 아래 목표를 가지고 공부를 할 것 입니다. 1. Thread의 개념 이해 2. APIs (Pthreads, Windows ,and Java thread libraries) 3. Thread의 기본적 특성 4. multithread programming 5. Window, Lin..
com24everyday.tistory.com
CPU Scheduling 에 대한 다음과 같은 순서로 배울 겁니다.
1. Basic Concepts
2. Scheduling Criteria
3. Scheduling Algorithms
4. Thread Scheduling
5. Multiple-Processor Scheduling
6. Real-Time CPU Scheduling
7. Operating Systems Examples
8. Algorithm Evaluation
CPU Scheduling 은 다중 멀티 코어의 가장 기본이 되는 요소입니다. 효율적으로 코어를 여러 프로세스가 사용할 수 있게 해줘야하기 때문입니다. 또한 사용자 입장에서는 다 동시에 실행되는 듯한 느낌을 줘야겠죠? 시작해보겠습니다.
Basic Concepts
단일 처리기 시스템에서는 하나의 프로세스만을 사용합니다. 나머지 프로세스는 사용 권한을 얻기 전 까지 기다려야하죠. 그래서 CPU utilization (CPU 이용률)을 극대화 시키기 위함입니다. 이는 코어에 항상 프로세스가 실행되게 하게 하는 겁니다.
어떤 Process의 실행(execution)은 CPU execution 과 I/O wait(입출력) 으로 구성이 됩니다. 이를 각각 CPU burst(빠름), I/O burst(느림) 라고 부르도록 합시다. 프로세스는 이 둘의 cycle 로 구성이 되어 있다고 말할 수 있습니다. 그럼 CPU utilization을 올리기 위해서는 어떻게 해야할까요? CPU burst 같은 빠른 동작이 많아져야 할 겁니다.
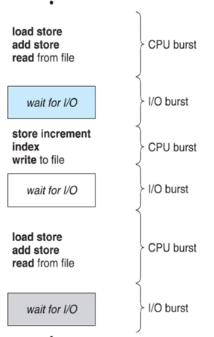
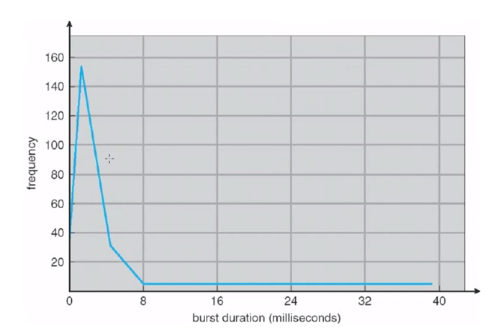
위 그래프는 CPU burst 들의 사용시간을 그래프로 표현한 겁니다. 보통 8미리세컨드보다 작은, 아주 빠른 cpu burst 가 많다는 걸 알 수 있습니다.
그럼 이게 왜 중요할까요? 이와 같은 시간들을 근거해서 CPU 프로세서를 할당하는 CPU Scheduling 의 기법을 만들 수 있기 때문입니다.
CPU Scheduler
저번 시간에도 나왔지만 CPU에 job을 할당하는 건 뭐가 해주나요? 네, Short-term scheduler 가 해줍니다. 이게 ready queue 에서 프로세스를 선택을 해서 CPU에 할당해줍니다. Short-term scheduler 가 CPU Scheduler 임을 알 수 있습니다.
그러면 CPU Scheduling은 프로세스가 어떤 상황일때 일어나는지 다음 4가지 상황을 살펴보겠습니다.
이는 CPU에 새로운 프로세스가 할당이 되는 시점을 생각해보면 됩니다.
1. switches from running to waiting state
: 어떤 프로세스가 실행되고 있는 상황(running)에서 기다리는 상황(waiting state)로 변한 겁니다. 그러면 CPU가 비기 때문에 다른 프로세스를 할당을 해줘야합니다.
구체적인 예시로는 실행되고 있던 프로세스가 I/O 요청으로 인해 ready queue 쪽으로 갑니다, 혹은 child process fork 후 child process 가 종료되기를 기다리는 상황 등이 있습니다.
2. switches from running to ready state
: 현재 실행하고 있던 프로세스가 ready queue 로 간 겁니다.
구체적인 예시로는 interrupt 가 발생해서 기다리는 형태로 전환되는 경우 등이 있습니다.
3. switches from waiting to ready state
: I/O 종료 후, 다시 CPU 실행을 기다립니다.
4. terminates
1과 4 상황에서는 스케줄링은 선택의 여지가 없습니다. 즉, 실행을 위해서 새로운 프로세스를 반드시 선택해야하는 거죠. 하지만 2,3 상황에서는 선택의 여지가 있습니다.
▶1과4 -> "기존 프로세스 종료 or I/O 를 위해 wait 상태' -> 새로운 프로세스 선택 -> 스케줄링 관점에서 보면 "기존 프로세스 실행이 종료된 후 새 프로세스 선택' -> 즉 non-preemptive scheduling 입니다. (비선점형 스케쥴링)
▶이와 달리 2와 3의 상황에서는 'interrupt 발생 혹은 I/O 종료'에 의해 기존 process 실행이 아닌 ready state에 있는 process 중에서 선택 실행 -> 스케줄링 관점에서 보면 preemptive scheduling 입니다.
※preemptive scheduling(선점형 스케줄링)에서는 다음과 같은 사항들을 고려해야합니다.
① 첫번째로는 공유한 데이터가 있는 경우
② 커널 모드에서 동작이 되는 경우
③ 그리고 이 interrupts을 어떻게 처리할거냐 라는 고려 사항들이 생깁니다.
① Consider access to shared data
이는 여러 프로세스가 데이터를 읽고 쓸 수 있다는 겁니다. 이럴 때는 경쟁 조건이 발생이 됩니다. 이를 통해 데이터가 바뀔 수 있기 때문에 주의가 필요합니다.
② Consider preemption while in kernel mode
어떤 프로세스가 system call 을 하면 커널 모드에서 동작이 일어나게 됩니다. 이 경우 preemption 이 발생을 하게 됩니다. 이를 통해 kernel 상에서 만들어진 많은 자료구조 같은 자료들에 변경이 발생할 수 있게 됩니다. 그러므로 주의가 필요합니다.
③ Consider interrupts occurring during crucial OS activities
어떤 중요한 운영체제 동작 중에 interrupts 가 발생이 됐습니다. 근데 이 처리를 통해 또 다른 인터럽트가 생기면 일관성에 문제가 생기게 됩니다. 그러므로 대부분의 OS 에서는 인터럽트 처리 동작 중에는 다른 인터럽트를 받지 못하게 disable 을 시킵니다.(병행처리 못하게) 그리고 이 과정이 끝나면 다시 interrupt enable 시킵니다.
Dispatcher
: short term scheduler 가 선택한 프로세스에 CPU 권한을 준다라는 의미입니다. CPU 권한을 얻는다는 건 프로세스가 실행된다는 겁니다.
▷Dispatcher 작업
- switching context , 기존의 프로세스를 쫓아내고 선택된 프로세스가 로드 되어야합니다.
- switching to user mode
- jumping to the proper location in the user program to restart that program, 적절한 시행 포인트를 찾습니다.
Dispatch latency
:기존 프로세스를 쫓아내고 선택한 프로세스를 시행하는데 걸리는 시간
Scheduling Criteria
스케줄링을 할때 어떤 것을 고려를 해야할까에 대해 이야기를 나눠보겠습니다.
- CPU utilization(이용율)을 극대화하자
- Throughput(처리량) : 중요, 단위 시간당 얼마나 많은 프로세스가 실행되고 있는가
- Turnaround time(총 처리 시간) : 이것과 구분이 되어하는 것이 아래의 Response time입니다. 어떤 task 의 처음부터 끝까지를 의미합니다. (complete a request 가 될때까지)
- Waiting time(대기 시간) : 프로세스가 ready queue 에 있는 시간
- Response time(응답 시간) : 어떤 프로세스가 실행이 될때 첫 응답이 오는데 걸리는 시간입니다.
Scheduling Algorithm Optimization Criteria

▶First-Come, First-Served(FCFS) Scheduling
:선입선출 알고리즘
다음과 같은 프로세스가 다음과 같은 순서로 온다고 생각해봅시다.
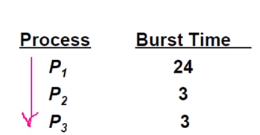
P1이 먼저 왔으니 먼저 실행이 됩니다. 백화점에서 장바구니에 가득 채운 사람 뒤에 음료 하나를 산 두 명이 기다리는 것과 같습니다.

P1은 처음 오자마자 실행됐으니 기다리지 않았습니다. P2 는 24초 그리고 P3 는 27초를 기다리게 됩니다. 평균 17초를 기다리는 겁니다.
이처럼 선입선출(FCFS) 방식이 공정할 수는 있지만 효율적인 알고리즘은 아닌겁니다.
그럼 P1이 빨리 왔다고 가정해봅시다. 그러면 다음과 같은 시간이 걸릴 겁니다.

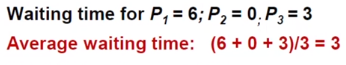
평균 대기 시간이 한참 줄어든 걸 볼 수 있습니다. 이를 통해 짧은 시간을 가진 것을 앞쪽에 배치하면 효율적이어진다는 사실을 알 수 있습니다.
이와 같은 FCFS 스케쥴링의 특성을 Convoy effect(starvation) 라고 합니다. 하나의 긴 프로세스 뒤로 짧은 프로세스가 쭉 나열되는 겁니다.

그럼 이제 FCFS 측면이 아닌 Shortest-Job-First(SJF) 스케줄링을 보도록 하겠습니다.
▶Shortest-Job-First(SJF)
:이는 CPU burst 시간이 짧은 process를 먼저 스케쥴링 하는 겁니다. (Process 전체 길이를 고려하는게 아닙니다)
이 SJF 는 최적(optimal) 한 방식입니다. 하지만 사실 많은 일이 일어나는 (dynamic 한 상황) 상황에서 프로세스들의 CPU burst time의 정보를 알 방법이 사실 없습니다. 그렇기 때문에 이전 CPU burst time 을 이용해서 예측을 하여 예측한 시간이 짧은 프로세스를 스케줄링 합니다.
사실 프로세스는 다음과 같은 I/O burst 와 CPU burst 가 섞여서 다양한 분기, 플로우를 가지기 때문에 실행하기 전까지 CPU burst time 을 알기란 사실상 불가능한 겁니다.
이처럼 SJF 는 최적의 알고리즘이지만 현실적으로는 어렵다는 것을 알 수 있습니다.
▷SJF 의 예시
프로세스 4개가 다음과 같이 들어왔을때를 가정해봅시다.

가장 짧은 프로세스를 먼저 실행시켜야합니다. 3인 P4 가 먼저 실행이 될겁니다. 그렇게 차례로 실행하면 다음과 같은 결과가 나올 겁니다.

Determining Length of Next CPU Burst
아까 전에 CPU burst time 을 정확히 알 수 없기 때문에 예측을 한다고 했습니다. 그 기법에 대해 알아보겠습니다.
exponential averaging, smoothing 기법이라고 합니다. 이 기법은 다음과 같은 슈도코드를 가지고 있습니다.

보면 tn은 실제 CPU burst time 을 가지고 있습니다.
그리고 타워n 은 다음(n+1) cpu burst time을 예측한 예측 시간입니다.
그래서 다음 예측시간은 현재 tn과 현재 예측 시간을 통해서 예측하겠다는 이야기입니다.
다음 표는 예측한 예시입니다.
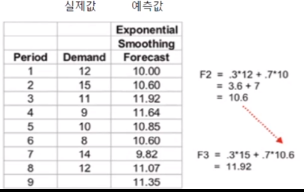
알파가 0이면 예측 값만을 가지고 예측을 한다는 거고 알파가 1이면 실제 CPU burst time 값만 가지고 예측을 한다는 의미인 겁니다.
▶Shortest-remaining-time-first
남아있는 잔여시간이 가장 적은 프로세스를 고르는 알고리즘입니다.
Preemptive SJF 라고 할 수 있습니다.

다음과 같은 프로세스 4개가 들어왔다고 생각해봅시다.

맨 처음 도착한 게 P1 이니깐 P1이 실행이 됩니다. 1일때 P2가 들어왔는데 burst time이 4이기 때문에 P2 가 실행이 됩니다. P3가 2에 들어왔을때는 P2의 burst time이 3 이기 때문에 P2가 쭉 실행이 돼서 5에 끝납니다. 그러면 P1 - 7, P2 - 9, P4 - 5이기 때문에 P4가 실행되고 P1,P3 순서로 진행이 됩니다. 그럼 평균 대기 시간은 다음과 같습니다.
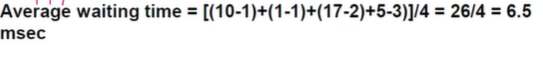
이는 Priority Scheduling 에 속합니다. 남은 시간이 짧은 거에 우선 순위를 두는거죠.
▶Priority Scheduling
:각 프로세스에 우선순위 번호를 부여하고 CPU는 우선순위가 높은 프로세스를 실행합니다.
SJF 도 일종의 우선순위 스케줄링입니다.
이런 스케줄링도 문제가 생기는데 기아현상(Starvation) 이 생깁니다. 낮은 우선순위의 프로세스가 절대 실행될 수 없다는 문제 입니다. 이에 대한 해결방안으로 Aging 이 있습니다. 시간이 지남 따라 우선순위를 높여주는거죠.
다음은 단순한 우선순위 스케줄링 예시입니다.
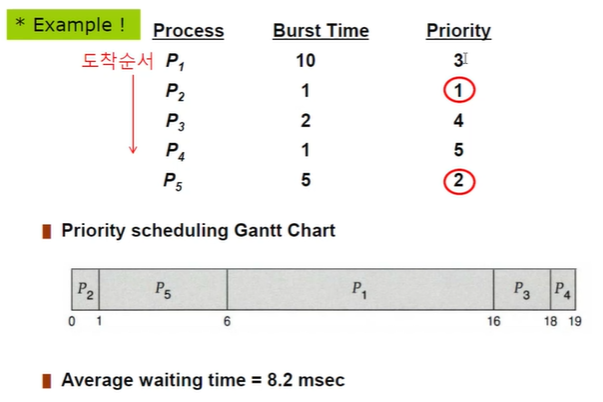
▶Round Robin(RR)
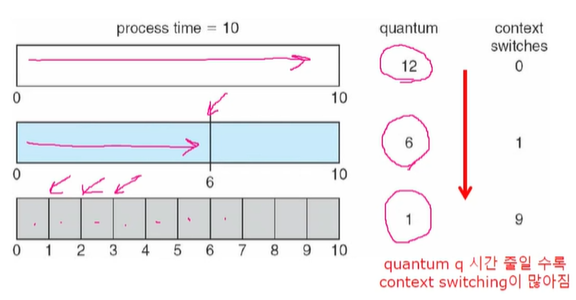
라운드 로빈 방식을 배워보겠습니다. 이는 시분할 시스템을 위해 설계가 되었습니다.. 어떤 프로세스는 어떤 정해진 시간 만큼의 CPU time 을 할당 받습니다. 프로세스가 길던 짧던 정해진 시간 안에 실행될 기회를 가지는 겁니다. 시간이 지나면 다른 프로세스로 실행 권한이 넘어가게 됩니다. (preempted) 그리고 이 프로세스는 ready queue 로 넘어가게 됩니다. 어떤 프로세스도 (n-1)q 시간 만큼 기다리지 않습니다.
만약 주어진 CPU time인 q가 커지면 어떻게 될까요? 이는 FIFO 와 같아지고 작으면 프로세스가 해결되기 전에 빠르게 switching 이 일어나기 때문에 오버헤드가 많아집니다.
그럼 q = 4인 라운드 로빈 방식의 예를 살펴보도록 하겠습니다.

다음과 같은 프로세스 3개가 들어온다고 가정해봅시다.
그럼 다음과 같은 진행 순서를 가지게 됩니다.

P1이 4초가 지나자 ready queue , 즉 실행순서가 뒤로 간 것을 알 수 있습니다.
RR 방식은 보통 평균 전체 처리 시간(turnaround)가 SJF 보다 깁니다. 하지만 응답시간(response) 은 짧습니다.
q는 보통 10ms ~100ms 사이입니다.
▶Multilevel Queue
: Ready queue 가 여러 큐로 구성
특성에 따라 다른 프로세스들이 할당이 됩니다.(일반적으로 메모리 크기, 프로세스 우선 순위 등)
foreground(interactive) - RR
background(batch) - FCFS
Multilevel Queue의 예시입니다.
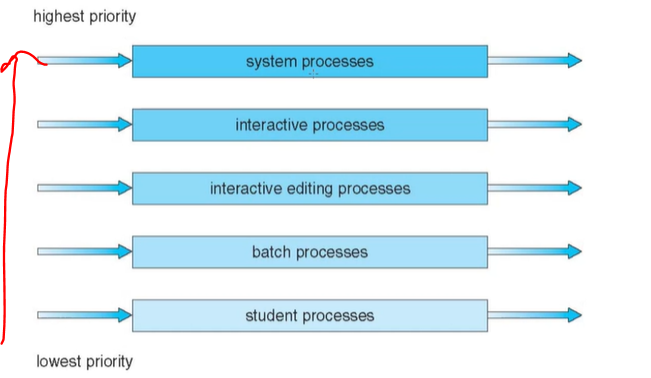
스케줄링은 반드시 큐 사이에서 일어나야하고 고정된 우선순위 스케줄이든(Fixed priority scheduling) 시간분할이든(Time slice) 든 방식을 쓰게 됩니다.
Multilevel Feedback Queue
프로세스가 다양한 큐를 이동할 수 있습니다. starvation 문제를 aging 으로 해결할 수 있습니다.

예시를 한 번 보겠습니다.
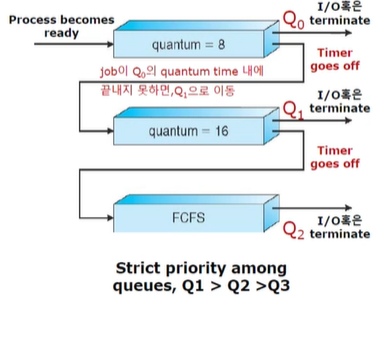
Q1과 Q2는 라운드로빈 방식으로 실행이 되고 Q3는 FCFS 방식을 사용합니다. 보면 Q1,Q2 에서 시간이 끝나면 다음 큐로 넘어가는 것을 알 수 있습니다.
실행시간이 30가량인 프로세스가 들어왔다고 가정해봅시다. 그러면 첫 큐에서 8이 주어집니다. 하지만 프로세스를 8안에 끝내지 못했기 때문에 Q2로 갑니다. 또 실행할 기회를 얻어서 Q2에서 프로세스가 실행이 되지만 16안에 못 끝냈기 때문에 Q3 로 가게 됩니다. 여기서는 FCFS 방식으로 실행할 기회를 얻게 됩니다.
▶Thread Scheduling
:프로세스 스케줄링과는 당연히 다릅니다. 스레드에는 LWP 개념이 있었습니다. thread library 가 주어지면 커널에 맵핑이 되는데 이때 LWP 개념으로 맵핑이 됩니다. 이런 경우에서 사용자 레벨 스레드는 LWP 상에서 동작이 되고 이를 통해서 동작이 되면 LWP 상에서 진행이 되어야합니다. 경쟁에 의해서 스케줄링이 됩니다. 즉 동일한 process 에 속하는 thread 간 경쟁을 하므로 "프로세스 경쟁 범위(process-contention scope,PCS)" 라고 합니다.
user level thread가 LWP 상에서 스케줄링 된다는 것은 thread가 실제 CPU상에서 실행중이라는 것을 의미하지 않습니다.
커널 스레드는 System-contention scope(SCS) "시스템 경쟁 범위" 로 시스템 레벨에서 경쟁을 합니다.
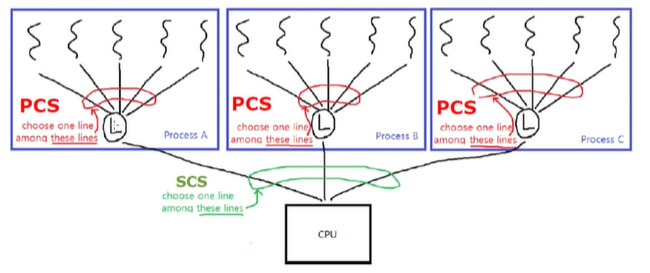
SCS가 선택하는 스레드가 실행이 되겠습니다.
프로세스에 스레드 개념이 도입됨에 따라서 스케줄링 되는 것은 프로세스가 아니라 스레드입니다.
그리고 스레드는 언급했듯이 사용자 레벨 스레드와 커널 레벨 스레드로 두가지 종류가 있었습니다.
또한 사용자 레벨 스레드를 커널 레벨 스레드로 맵핑할때 Many-to-one 과 many-to-many 와 같은 맵핑 방식이 있었습니다. 그리고 이 둘은 LWP 라는 곳에 스케줄링, 맵핑했습니다. 이 수준을 PCS(Process-contention scope) 즉 '프로세스 경쟁 범위' 라고 하였습니다. 우선순위는 프로그래머가 우선순위를 정할 수 있습니다.
물론 user level thread 가 LWP 상에서 스케줄링 된다는 건 스레드가 실제 CPU 상에서 실행중이라는 것을 의미하지 않습니다. 실제로 CPU 상에 맵핑 되기 위해서는 커널 레벨 스레드가 CPU 에 스케줄링이 되어야합니다. 이렇게 어떤 커널 레벨 스레드를 고를 것인지 정하는 것을 SCS(System Contention Scope) 라고 합니다.
Pthread Scheduling 에서는 이처럼 어디에서의 스케줄링인지를 실행하기 위해 API 를 제공합니다.그리고 운영체제마다 허용하는 범위의 경쟁이 다른데 Linux와 Mac 에서는 System 영역만 제한이 됩니다.
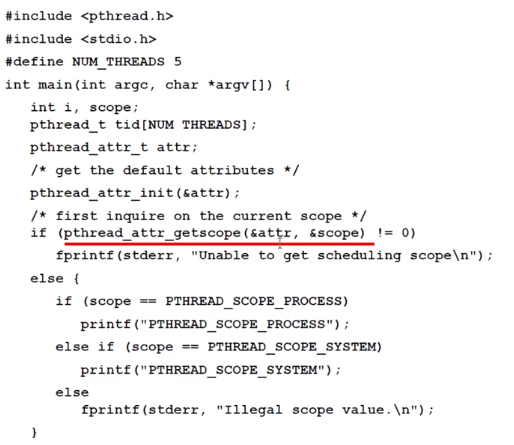
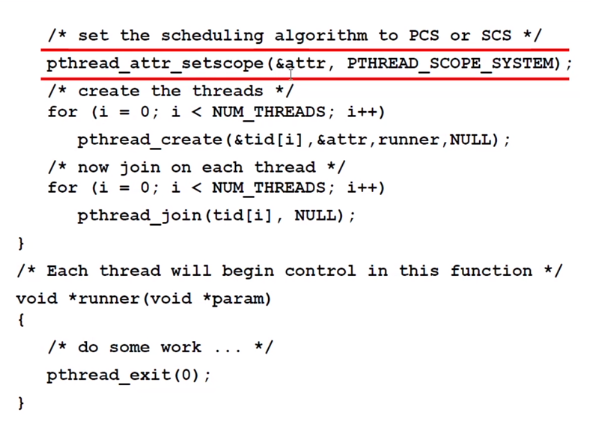
이렇게 이때까지는 프로세서가 하나인 거에 대해서만 스케줄링을 살펴봤습니다. 이제는 프로세서가 여러개인 경우를 한 번 살펴 보겠습니다.
Multiple-Processor Scheduling
프로세서가 여러개일 경우에도 개념은 비슷합니다.
- 프로세서들이 동일한 기능을 가진다고 가정
- Asymmetric multiprocessing : 스케줄링이 오직 하나의 데이터에 접근 합니다.
이 경우에는 멀티 프로세서라는 개념이 별로 중요치 않습니다.
- Sysmmetric multiprocessing(SMP) : 각각의 프로세서가 동일하게 데이터를 엑세스를 할 권한이 있습니다.
실제로 이 개념이 중요하고 가장 많이 쓰입니다.
Processor affinity(프로세서 친화성) : 프로세서을 할당을 할 때 알아두어야할 개념입니다.
'어떤 프로그램은 어떤 프로세서에 친화성이 있다. ' 라는 게 무슨 말이냐면 특정 CPU, 특정 코어에 할당되면 성능이 더 좋은 그런 친화성을 가진다고 볼 수 있습니다.
- Soft affinity : OS 가 동일한 처리기에서 프로세스를 실행시키려고 노력은 하지만, 보장하지는 않습니다.
- Hard affinity : 시스템 호출 단계에서 이미 프로세스는 어디서 처리를 할지 명시되어 있습니다. (보장)
멀티코어를 가지는 메모리의 구조 자체가 프로그램의 친화성에 영향을 줄 수 있습니다.
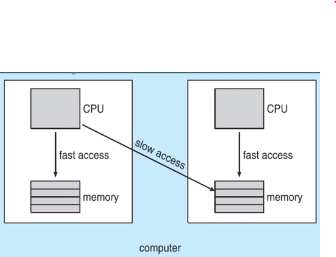
다음과 같은 NUMA(누마) 는 Non-uniform Memory Access 로 자기 자신의 메모리를 접근 할때는 빠르고 다른 메모리를 접근할땐 속도가 느립니다. 이게 Memory Access 속도가 균일하지 않다는 겁니다. 그럼 만약에 어떤 프로세스가 왼쪽의 memory에 접근할 일이 더 많다면 어느 코어에 할당이 되어야할까요? 당연히 왼쪽입니다.
멀티프로세서 스케줄링을 하는 이유는 또 무엇이 있을까요?
바로 Load Balancing (부하 균등화)입니다.
이 같이 Sysmmetric multiprocessing(SMP) 상에서는 모두가 동일한 부하를 가져서 속도를 높이는 게 또 하나의 목적입니다. 부하를 줄이기 위한 두가지 방법이 있습니다.
1.Push migration : 특정 태스크가 주기적으로 각 프로세서를 체크합니다. 만약 과부하가 된 프로세서가 있다면 그 태스크를 다른 널널한 프로세서에 분할해줍니다.
2.Pull migration : 널널한 프로세서(idle) 가 바쁜 프로세서의 대기중인 태스크를 끌고 옵니다. (processor 가 함)
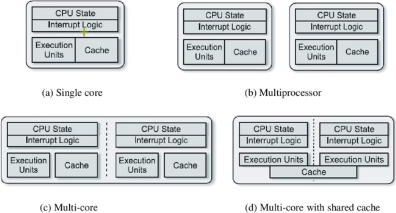
위 그림을 보면서 Multicore와 Multiprocessor 의 차이를 잘 알아두어야합니다.
-Multicore Processors
빠르고 저전력입니다.
다중 코어 프로세서 상에서 특정 프로세스가 메모 접근시 available 한 데이터를 얻을 때까지 많은 시간이 소요됩니다. -> memory stall 이 발생합니다.
이는 cache miss 에 의해 발생하는 경우가 많습니다.
스레드에 대한 스케줄링을 할때는 이런 Memory stall 현상을 적극 이용을 해서 전체적인 스케줄링을 할 수 있습니다.
코어에 여러 스레드 할당
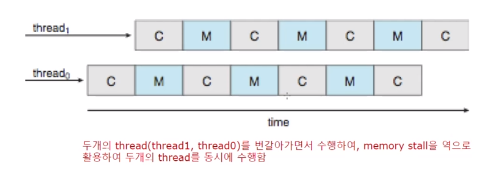
각각이 다른 스레드가 Memory stall에 실행이 됩니다. 이렇게 활용을 할 수 있습니다. 이러면 단일 코어의 효율이 높아질 수 있습니다.
Real-Time CPU Scheduling
- Soft real-time systems : critical real-time process 가 특정한 시간까지 스케줄링 되는 것을 보장하지 않습니다.
- Hard real-time systems : 반드시 특정 시간까지 실행이 됩니다.
- Event Latency : 이벤트가 발생해서 그 이벤트에 대한 서비스가 수행 될 때 까지의 시간. 즉 real- time system이 반응하는데 걸리는 시간입니다.
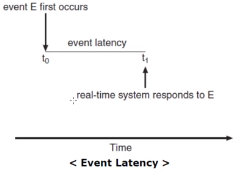
실시간 시스템의 성능에 영향을 주는 두가지 주요 요소
1. Interrupt latency : 인터럽트가 발생을 해서 그 인터럽트를 처리할때 까지의 시간 (ISR. Interrupt Start Routine)
- Interrupt latency 에 영향을 주는 요인 중 하나는 Kernel data 구조가 update 되는 동안 interrupt를 disable 시키는 겁니다. 그러면 latency는 더 길어질 수 밖에 없겠죠.
2. Dispatch latency : 현재 프로세스가 blocking 이 돼서 다시 실행되기 까지의 시간
앞에서 배웠지만 다시 한번 Dispatcher 의 개념을 살펴보자면 OS 가 스케줄링을 해서 선택한 프로세스를 실행할 수 있게 set up해줍니다. 이게 빠르면 좋겠죠?
-Conflict phase :
1) 커널 상에서 시행되고 있는 동작을 없앱니다.
2) 쫓겨나는 프로세스가 사용하던 리소스를 대체되는 프로세스가 사용될 수 있게 만들어줍니다.
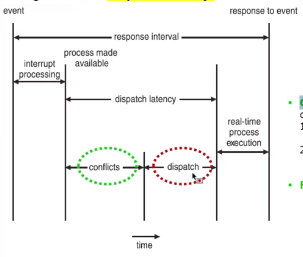
▶Priority-based Scheduling
:이제 우선 순위를 가지는 스케줄링에 대해 알아보겠습니다.
실시간 OS(Real time OS) 에서는 실시간 프로세스가 CPU를 필요로 할 때, 바로 응답을 해주어야합니다. 그래서 이전에 이 실시간 OS를 두가지 관점으로 보았습니다. 하나는 Soft real-time 이고 또 하나는 Hard real-time 이었습니다. 이 둘의 차이는 'Deadline 반드시 지켜야하냐'였습니다. 또한 Soft real-time 은 선점적(preemptive)이고 우선순위 기반 스케줄링(priority-based scheduling) 이었습니다.
본격적으로 우선순위 기반 스케줄링을 보기 전에 Process 의 task 속성을 살펴보겠습니다.
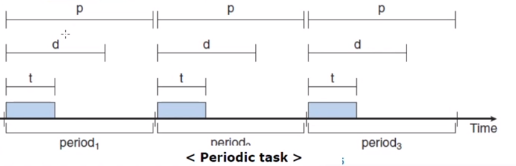
파랗게 색칠 되어 있는 것이 task 고 p주기로 반복되고 있음을 볼 수 있습니다. 1/p 를 주기적인 task 의 발생율(Rate)이라고 하겠습니다. 그리고 따로 표시된 d는 데드라인을 의미합니다. 만약 특별히 d 가 주어지지 않으면 보통 p 가 데드라인으로 적용됩니다.
▶Rate Monotonic Scheduling
: task의 주기에 따라서 스케줄링의 우선순위를 결정하는 Rate Monotonic Scheduling 에 대해 배워 보겠습니다. 이 기법의 이름을 보면 무슨 의미인지 예측할 수 있습니다.
조금 전에 이야기한 발생율(Rate) 이 있습니다. 주기가 짧아질 수록 이 발생율은 커집니다.
Monotonic는 수학에서 Monotonic function은 단조함수라고 합니다. 이 특성을 살펴보면 계속 상승, 계속 하강 둘 중 하나입니다.
그럼 Rate Monotonic Scheduling은 뭐냐?
발생율이 클수록, 즉 주기가 짧을 수록 우선순위를 높히는 스케줄링 기법입니다.

예시)
두 개의 프로세스 P1, P2를 생각하겠습니다.
각각의 주기는 p1 = 50, p2 = 100 //이 기법에 의하면 P1의 우선순위가 높은 겁니다.
수행 시간은 t1 = 20, t2 =35
그리고 우리가 스케줄링에 대해 논할 때는 이 프로세스가 데드라인을 만족시키는 지를 살펴보아야합니다.
일단은 CPU utilization 에 대해 먼저 이야기 해봅시다.
P1 = 20/50 = 0.40
P2 = 35/100 = 0.35
이 둘을 단순 합산 하면 75% 의 utilization을 사용합니다. 1보다 작기 때문에 이 두 프로세서를 실행을 시킬 경우 데드라인을 지킬 수 있을 겁니다.
방금 상황의 실제 예시를 보겠습니다.
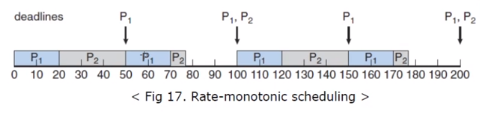
P1의 주기는 50입니다. 그러니 50,100,150 에서 실행이 되어야합니다. 주기가 50이기 때문에 50마다 P1 프로세스가 실행된다는 걸 알 수 있습니다. P2는 100이 주기이기 때문에 100 그리고 200 에서 실행이 되고 있습니다.
0에서 대기하고 있는 프로세스는 P1과 P2 입니다. 하지만 Rate Montonic이기 때문에 P1의 주기가 더 짧으니 우선순위가 더 높죠. 그래서 P1이 먼저 실행이 되는 겁니다. P1이 20동안 진행이 됩니다. P2는 완료될려면 35 가 필요합니다. 하지만 30 시점에서 P1이 새롭게 스케줄링이 되죠. 우선순위가 더 높으니깐 P2를 preemptive 되어 버립니다. P1의 20이 끝나자마자 다시 실행이 됩니다. 나머지 5가 실행되면서 끝납니다.
즉 P2가 실행되고 있어도 P1가 Preemptive(선점)해버립니다.
그리고 또 다른 특성으로는 Rate Monotonic Scheduling으로 스케줄링 할 수 없는 경우 다른 static priority 알고리즘으로도 스케줄링 할 수 없는 것으로 알려져 있습니다.
다음 또 다른 예를 보겠습니다.

P1 의 주기 p1 = 50, t1 = 25
P2 의 주기 p2 = 80, t2 = 35
P1의 우선순위가 높습니다. 보면 P2가 25~50 까지 진행되다가 P1에 의해 Context Switching 이 일어납니다. 이때 50에서 다시 75를 끝내고 P2가 reload 되는데 5를 실행하고 데드라인 = 80 을 만족못하고 죽어버립니다.
▶Earliest Deadline First Scheduling(EDF)
:이는 프로세스의 데드라인이 얼마나 임박했느냐에 따라서 우선순위가 결정이 됩니다.
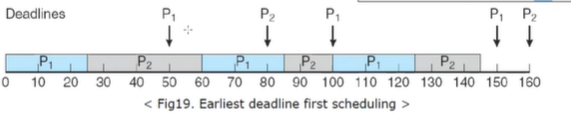
이는 상황에 따라서 우선순위가 동적으로 (dynamic)하게 변화합니다. 위 그림은 그전 사례와 동일합니다.
P1 의 주기 p1 = 50, t1 = 25
P2 의 주기 p2 = 80, t2 = 35
여기 50을 보면 P2가 쫓겨나지 않고 계속 프로세스를 진행하는데 이는 데드라인이 더 빠르기 때문입니다.
P2의 데드라인은 80이고 50의 P1은 100이기 때문입니다. P2의 우선순위가 더 높은 겁니다.
▶Proporional Share Scheduling
:일정한 자신의 몫을 가지고 스케줄링을 받는다는 뜻입니다.
모든 프로세스의 해당되는 share가 T개입니다.
이때 하나의 응용이(Application)이 N개의 share을 가지고 있다면 당연히 N<T일겁니다.
예를 한 번 들어보겠습니다.
T=100 인 time share가 있으며 3개의 프로세스 A,B,C가 있다고 가정합시다.
A<-50 B<-15 C <-20 을 할당할때 A는 모든 처리기 시간의 50%, B는 15%,C는 20%를 할당 받는 겁니다.
이때 만약 새로운 프로세스 D가 20을 할당받고 싶다고 하면 가능할까요?
A+B+C = 85이기 때문에 D가 20을 할당 받는 것은 불가능 합니다.
Proportional share scheduling(일정 몫 할당 스케줄링)은 프로세스가 특정 시간 share를 할당받는 것을 보장하는 "승인 제어 정책"과 함께 동작해야합니다.
POSIX Real-Time Scheduling
이제 실시간 스케줄링 표준을 보도록 하겠습니다.
'POSIX.1b' 가 바로 그 표준입니다.
이 표준에는 실시간성이 요구되는 real-time threads 에 대한 두가지 표준을 제시하고 있습니다.
1. SCHED_FIFO
2. SCHED_RR
여기서 라운드 로빈 방식이 있다는 건 타임 슬롯 방식이 있다는 것과 선점이 될 수 있다는 걸 이야기 하기도 합니다.
그리고 get,set을 할 수 있는 API 가 제공이 됩니다.


현재 셋팅된 스케줄 정책을 확인합니다.

사용자가 또다른 형태의 스케줄링을 셋팅하는 걸 볼 수 있습니다. 그리고 runner 함수가 등록되는 걸을 확인할 수 있습니다.
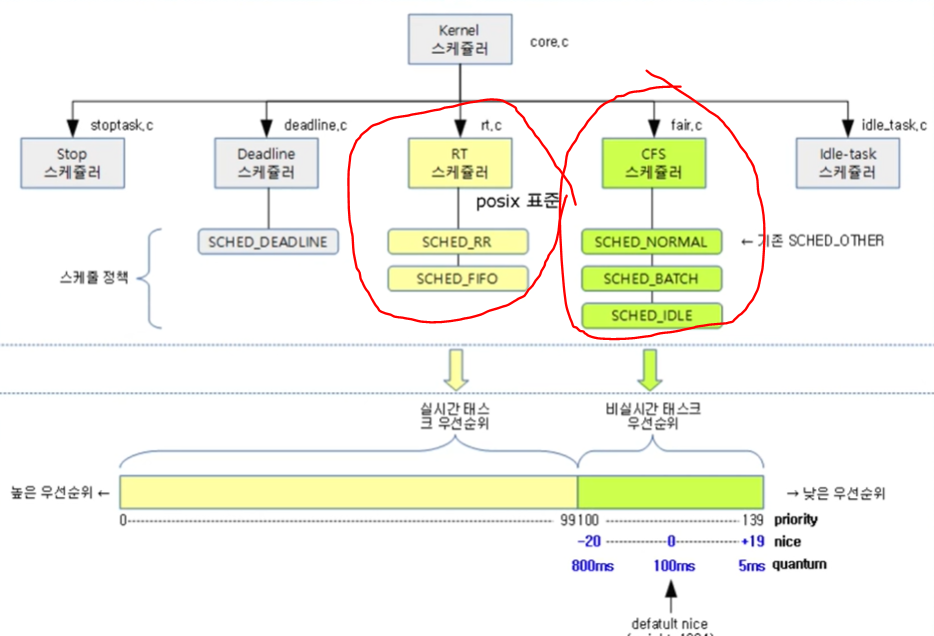
Linux scheduling
이제 중요한 Linux scheduling 에 대해 알아보겠습니다.
- 사용되고 있는 리눅스 스케줄러,CFS
- Real-time Scheduler for Linux
Linux Scheduler - O(1)
여기서 프로세스를 두가지 타입으로 나눌 수 있습니다.
-Scheduling real time processes
Priorities from 0 ~ 99 (높은 우선 순위)
- Scheduling normal processes(Interactive, Batch)
Priorities from 100 ~ 139
단점은 외부에서 입력이 필요한 Interactive process 의 response times 입니다. 계속 우선순위가 밀리게 됩니다.
이걸 보안하기 위해 나온 것이 CFS 입니다.
Linux Scheduler-CFS
Completely Fair Scheduler
:프로세스에 따라서 너무 우선순위가 밀리는 문제를 해결하고 프로세스들을 공정하게 처리하겠다는 철학을 가지 스케줄러입니다. I/O and CPU bound processes 을 잘 처리하겠다는 그런 스케줄러 입니다.
물론 여기서도 프로세스를 1. default( O(1) 에서의 normal processes) 와 2. real-time 으로 나눕니다.
CFS에서는 자신을 낮춤으로써 우선순위를 높여주는 nice value 라는 게 있습니다.
- 적은 값이 높은 우선순위를 가집니다.
- Calculates targeted latency(목적 지연시간) : task 가 무조건 한 번 실행되는 시간 단위를 의미합니다.
- Targeted latency는 실행되고 있는 task 가 많아지면 높아질 수 있습니다.
CFS scheduler는 vruntime 이라는 가상의 변수를 이용해서 virtual run time(actual run time, 실제 실행이 된 시간) 으로 실행을 시킵니다. CFS 를 구현할 때 이 virtual run time 을 이용해서 Fair 하게 하는 역할을 합니다.
예를 들어봅시다.
다음 과 같은 네개의 프로세서가 있습니다.
A-8ms
B-4ms
C-16ms
D-4ms
그리고 targeted latency는 4ms 입니다.
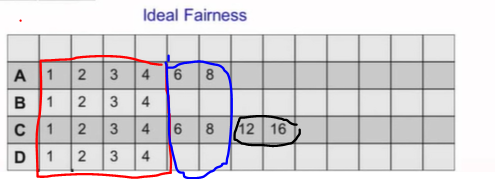
네 개의 프로세스니깐 1ms 씩 나누어서 실행됩니다. B,D가 끝난 이후 A,D가 2ms 씩 이를 나눠서 실행하고 A가 끝난 이후 C가 12,16 실행되고 끝납니다.
taget latency 는 결국 응답시간(response time)을 보장해주는 개념입니다.
실제로는 입출력이라든지 다양한 요소들의 인하여 이렇게 Ideal한 상황이 나오기는 힘들겠죠.
target latency 의 단점은 만약 나누어야 하는 프로세스가 100개 인데 단일 코어밖에 없다면 Context Switching 을 하는데 시간을 다 보내게 된다는 겁니다. 그래서 throughtput(처리하고 있는 프로세스)을 보장해주기 위해 Mininum Granularity 를 도입할 필요가 있었습니다. 이는 최소한으로 할당되는 시간에 제한을 걸어두어서 이거 보다 작은 시간이 나오면 targeted latency 자체를 줄여버립니다.
다시 CFS로 돌아가서 가상 변수 vruntime 에 대해 알아보겠습니다.
vruntime의 의미를 '프로세스가 지금까지 얼마나 많은 CPU time을 얻었는지 알려준다.' 입니다. 프로세스 간의 fair 한 스케줄링을 위해 그동안 적게 실행된, ,즉 vruntime이 적은 프로세스에게 높은 스케줄링 우선순위를 줍니다.
그래서 왜 virtual run time 개념이 나왔는지에 대해 이야기 해보겠습니다.
physical execution time , 실제 실행 시간 뿐만 아니라 nice value 까지 고려해야합니다. 즉 실행되는 시간에 여러가지 weight 시간을 적절히 나눠서 nice value를 곱하면 vruntime 이 나옵니다.(사실 책 마다 좀 다른 값이 됩니다.)

두 스케줄러에 대해 집중적으로 배워보았습니다.
Windows Scheduling
-윈도우 스케줄링은 우선순위 기반 선점적 스케줄링입니다. 당연히 우선순위가 높은 스레드가 다음에 실행되는 스레드이겠죠.
-또 윈도우 스케줄링에서는 Dispatcher 가 곧 scheduler 입니다.
- 그리고
1. 스레드가 blocked
2. 할당된 time slice 이 끝났을 때
3. 우선순위가 더 높은 스레드에게
선점 되기 전까지 실행이 됩니다.
- Real-time thread는 non-real-time thread를 선점할 수 있습니다. 우선순위가 높기 때문입니다.
- 32개 레벨의 우선순위를 가집니다.
- Priority 0은 memory-management thread 입니다.
- 그리고 각 우선 순위를 위한 queue가 존재합니다.
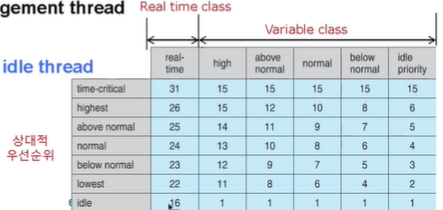
테이블을 보면 Real time class 와 Variable class 가 있습니다. 보면 스레드가 여러 클래스가 있고 그 안 에서도 상대적 우선순위가 존재합니다.
일반적으로 스레드가 생성될때, 해당 스레드가 속한 class에서 기본, normal 우선 순위를 배정 받습니다.(네번째 줄)
실시간 스레드면 24, normal 클래스면 8이 되겠습니다.
Solaris(솔라리스)
이제 솔라리스의 스케줄링을 보겠습니다.
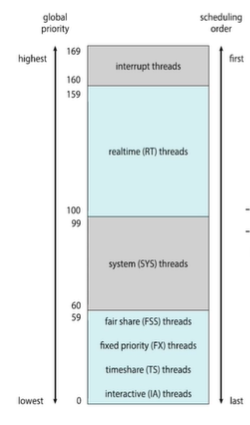
기본적으로 역시 Priority-based 즉 우선 순위 기반 스케줄링입니다. 총 여섯개의 classes 가 존재합니다.
-Time sharing(defalut) (TS)
-Interactive(IA)
-Real time(RT)
-System(SYS)
-Fair Share(FSS)
-Fixed priority(FP)
그리고 스레드는 하나의 클래스에 속하게 됩니다.
각각의 클래스는 고유한 스케줄링 알고리즘을 갖고 있습니다. (Time sharing 은 multi-level feedback queue 알고리즘을 사용합니다.)
다음 표는 Time Sharing 과 Interactive Scheduling classes 의 Dispatch 사례입니다 .
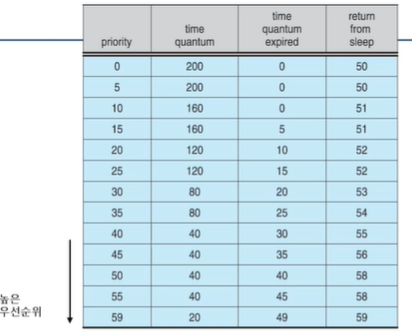
보면 우선순위 외에도 세가지 추가 열이(time quantum,time quantum expired, return from sleep) 존재합니다.
마지막 우선순위를 보면 time quantum 이 20으로 가장 작습니다. 이는 우선순위와 시간할당량(time quantum)이
반비례 관계라는 것을 알 수 있습니다. 왜 이럴까요?
Interactive(대화형 프로세스) 가 높은 우선순위를 가지고 CPU 위주의 프로세스는 낮은 우선순위를 가지는데 이는 입출격과 관계있는 Interactive 프로세스에 좋은 response time(응답시간) 을 제공하고 CPU 위주 프로세스는 좋은 throughput 특성을 가지게 하기 위함입니다.
그럼 time quantum expired 가 즉 타임 퀀텀이 만료되면 어떻게 할까요?
그때의 새로운 우선순위에 대한 정보가 나와있습니다.(시간 아닙니다.)
즉 첫번째 줄 에서 200의 시간이 지나면 우선순위가 0이 된다는 말입니다.
전체적으로 보면 시간 내 만료 못하면 우선순위를 점점 낮게 줘서 처리시간을 적게 준다는 것을 알 수 있습니다.
그럼 맨 오른쪽 return from sleep 은 무슨 의미일까요?
입출력 I/O wait 라든지 sleep 상태에서 복귀한 스레드가 가질 수 있는 우선순위입니다. 보면 전체적으로 우선 순위가 높은것을 볼 수 있습니다. 이는 입출력이 끝난 스레드의 response time(응답시간)을 줄이기 위한 겁니다.
솔라리스 클래스는 아래와 같은 우선순위를 가집니다.
이때까지 리눅스,윈도우,솔라리스에서의 스케줄링에 대해 알아보았습니다.
이 장에서는 Algorithm Evaluaiton 에 대해 알아보겠습니다.
말그대로 스케줄링 알고리즘의 평가입니다.
이미 정해져있는 workload를 통해서 분석하고 평가 하는 것을 'Deterministic modeling'이라고 합니다.
아래의 세가지 스케줄링에 평가 예시가 있습니다.
다음은 미리 정해져있는 워크로드입니다.


average waiting time을 구했습니다. 이는 응답시간을 구했다는 말과 동일하죠. 보면 SFJ 가 가장 적합한 스케줄링이라는 사실을 알 수 있습니다.
사실 많은 시스템에서 실행되는 프로세스는 너무 다양하기 때문에 이런 deterministic modeling 을 사용하기는 어렵습니다. 그렇기 때문에 'Queuing Theory'로 성능평가를 합니다. 이는 CPU와 I/O burst 의 확률분포를 계산합니다. 대표적으로 Little's Formula 가 있습니다. 그리고 이 방법의 제한적인 걸 보안한게 Simulation입니다. 직접 다 돌려보는 거죠. 그리고 궁극적인 마지막 방법은 직접 'Implementation' 구현 하는 겁니다.
이렇게 챕터 5 CPU Scheduling 에 대해 배워보았습니다! 수고하셨습니다.
1. Basic Concepts
2. Scheduling Criteria
3. Scheduling Algorithms
4. Thread Scheduling
5. Multiple-Processor Scheduling
6. Real-Time CPU Scheduling
7. Operating Systems Examples
8. Algorithm Evaluation
'공부 > 운영체제' 카테고리의 다른 글
| 운영체제7 Deadlock (0) | 2020.07.03 |
|---|---|
| 운영체제6 Process Synchronizaiton (0) | 2020.07.03 |
| 운영체제4 Threads (0) | 2020.06.17 |
| 운영체제3 Processes (1) | 2020.06.14 |
| 운영체제_1 (0) | 2020.04.18 |



