인공지능 보안의 취약점
-Adversrial Attacks & Defenses
머신러닝은 다양한 분야에서 뛰어난 성능을 보여주고 있지만 악의적인 데이터로 인해 오동작을 하는 등 Adversarial Attack 에 매우 취약
Adversarial Attack 유형
Poisoning Attack
- 잘못된 학습 데이터를 주입하여 오동작 발생하게 하는 공격
Evasion Attack
-가장 연구가 활발히 일어나는 분야
학습 단계가 아닌 분류 단계에서 데이터를 변조하여 오동작 발생하게 하는 공격
Model Extracion Attack
- 인공지능의 동작을 모사하여 정보를 추출하는 등의 공격
Inversion Attack
-반복적으로 질의하여 학습에 사용된 데이터를 추출하여 정보의 프라이버시를 침해하는 공격
(Bool SQL Injection 과 비슷한 느낌)
공격 유형
Backdoor Attack
DNN에 있어 Trigger 가 추가된 이미지 데이터는 특정한 label로 오분류하도록 하는 공격
즉 학생과 교수를 구분하는 DNN이 있다고 가정하였을 때 학생에 '안경'이라는 trigger 을 삽입하였을 때 교수로 인식하게 만드는 거. 이를 backdoor 를 주입한다고 한다.

Latent Backdoor Attack
transfer learning 기법 : 구글과 같은 거대 IT 기업에서 제공하는 미리 학습이 된 모델 (Pre-trained model = Teacher model)을 사용하여 원하는 데이터에 맞게 추가적으로 학습하는 기법
Latent Backdoor 는 Transfer Learning 과정에서 Teacher model 에 Backdoor 을 숨기는 것
이의 장점은 Target label의 흔적을 지우는 거다. 즉 노드를 삭제해 나중에 학습을 시켜도 이전에 Target label 로 분류가 일어나지 않는다.
Evasion Attack
위에서 언급했듯이 학습 데이터가 아닌 분류해야할 데이터를 최소한으로 변조하여 사람은 알아차리지 못하지만 인공지능은 오인식 하도록 만드는 기법, 대표적으로는 Adversarial Example 공격 기법 존재.
아래의 그림을 보면 우리의 눈으로는 알아채릴 수 없을 변조로 오작동을 이끌어낸다.
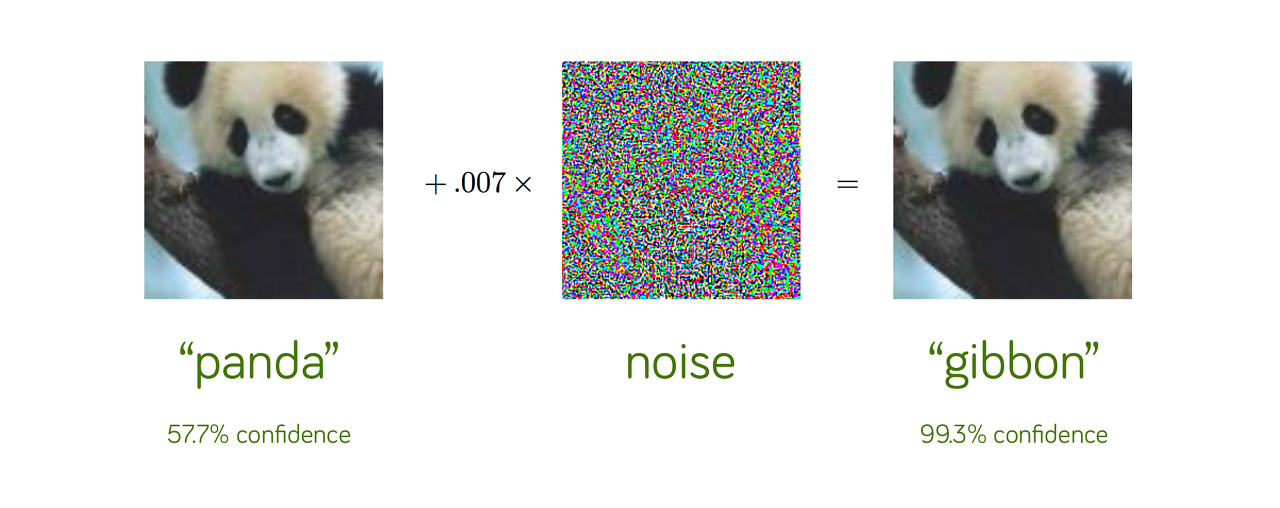
Model Extraction Attack
학습을 마치고 동작하는 인공지능의 동작을 모사하여 학습 데이터 구축 비용없이 반복적인 질의를 통해 인공지능이 출력하는 답을 획득하여 모델의 동작을 모사하는 것이다.
Inversion Attack
학습된 인공지능에 반복적으로 질의를 하여 학습에 사용된 데이터를 추출해 내는 공격
학습 데이터의 프라이버시 침해 가능

Adversarial Example 개요
- DNN이 오동작하게 만드는 input data 로 real data에 사람이 인식할 수 없을 정도의 작은 noise 를 추가하여 생성
Threat Model
- Adversarial Example 생성하여 DNN 을 공격하는 Model
다음과 같이 4가지로 구분할 수 있다. 논문을 읽는데 자주 나오는 단어들이니 반복 학습해놓자.
Adversarial Falsification
직관적으로 참을 거짓으로, 거짓을 참으로 오인식하게 하는 공격
-False positive attacks
Negative sample 을 positive 로 오인식하게 만드는 공격
-False negative attacks
Positive sample 을 negative 로 오인식하게 만드는 공격
Adversaryis Knowledge
- White-box attacks
모델의 구조에 대해 다 알고 있는 상태에서 이루어지는 공격
- Gray-box attacks
모델의 구조에 대해서만 알고 있는 상태에서 이루어지는 공격
- Black-box attacks
모델에 대해 아무것도 모르는 상태에서 이루어지는 공격
현재 White-box attack 을 방어 할 수 있는 방법은 나오지 않았다고 한다. 이에 대한 연구가 활발히 이루어지고 있다고 ...
transferability 라는 특성이 있어서라는데 이는 말 그대로 어떤 모델에서 통한 공격이 다른 모델에서도 통할 공격일 가능성이 높다는 것을 의미한다.
세상에는 참으로 다양한 공격 기법과 방어 기법이 존재한다.
(앞으로 스터디를 통해 깊게 파고들 내용들, 오늘은 개관만 했다.)
공격기법
1. L-BFGS
2. FGSM
3. BIM/PGD
4. DAA
5. C&W
6. JSMA
7. Deepfool
-------------------
스터디를 하면서 하나하나 깊게 알아볼거고 다 처음 보고 들은 개념이라 틀린 점이 있으면 댓글 남겨주세요!
1. L-BFGS
이미지 분류에 많이 사용되는 알고리즘, 다른 곳에도 적용은 가능
min x||x-x'||p subject to f(x') = y'
이는 노이즈를 최소화 해서 값이 다른 값이 되게 만드는 것
c||x-x'||p + J(델타,x',y')
여기서 c를 조절해서 최적의 adversarial 을 만든다.
다루기 힘들고 시간이 많이 걸리는 비효율적인 공격이다.
거의 처음 나온 공격 알고리즘이기 때문에 그럴만도.
2. FGSM
Fast gradient sign method
이는 untarggeted attack으로 빠르다.
미분 값을 구하면 바로 실행되는 one-step attack 알고리즘이기 때문이다.
이름에서 알 수 있는 거처럼 인공지능은 기울기를 따라서 최적화가 된다고 볼 수 있는데 여기서는 기울기를 반대 방향으로 하게 해서 Loss 최적이 되지 않게 하는 거다.
x' = x + E sign[dlel xJ(델타,x,y')]
여기서 플러스를 마이너스로 바꿀 경우 targeted attack이 된다.
3. BIM/PGD
이는 FGSM 을 반복한다고 생각해도 된다.
x't+1 = Clip[x't + \alpha sign[del x J(델타,x't,y]}
에서 Clip 은 특정값을 못 넘게 일반화 하는 것이다.
4. DAA
Distributionally adversarial attack으로 분포로 추정하는 데이터다.
max\um\int J(델타,x',y) d\um + KL[\um (x') || 파이(x)]
뮤 를 찾는 것이 핵심이다.
5. C&W
Carlini and Wagner attack. PGD 와 함께 많이 쓰이는 알고리즘이다. optimization-based adversarial attacks 이다. 모든 norm(차원) 에서 다 사용이 가능하다.
6. JSMA
여기서는 Jacobian matrix를 사용하는데 이 값이 input 어디에 가장 영향이 큰지, 어디에 가장 많이 영향을 미치는지를 파악한다.
7. Deepfool
이는 2차원을 기반으로 한다고 논문에 나와 있지만 다른 차원도 가능하다. 이는 최소한의 노이즈, perturbation으로 근사된 라인을 넘어보자는 것이다. 구불구불한 라인도 근사시켜 영역을 만들어 낼 수 있다.
앞으로의 스터디 최선을 다해 참가해야겠다!
모든 분들이 나보다 뛰어나신 분들이니 배울 점이 많을거 같다.
'스터디 > 인공지능 논문 읽기' 카테고리의 다른 글
| 논문 요약하기 : Zeroth Order Optimization (ZOO) (0) | 2020.11.20 |
|---|---|
| 과제1. 머신러닝 강의 듣고 요약하기 (0) | 2020.10.28 |
