자료형에 대한 이해는 모든 프로그래밍 언어의 시작이라고 할 수 있다.
파이썬의 자료형은 C/C++, 자바와 같은 다른 언어에서 사용되는 기본 자료형을 제공할 뿐만 아니라 사전 자료형, 집합 자료형 등의 유용한 자료형을 기본으로 내장하고 있어 매우 편리하다.
수 자료형(Number)
: 데이터는 모두 수로 표현할 수 있다. 대부분의 프로그램에서는 일반적으로 정수와 실수가 많이 사용되고 그 중에서도 정수가 기본으로 사용된다. 실수는 오차 범위 때문에 예기치 못한 오류를 범하기도 쉬고 정확성도 떨어진다. 실제로 코딩테스트에서도 대부분 정수를 다루는 문제가 출제된다.
1. 정수형(Integer)
- 양의 정수, 음의 정수, 0
2. 실수형(Real Number)
- 소수점 아래의 데이터를 포함하는 수 자료형
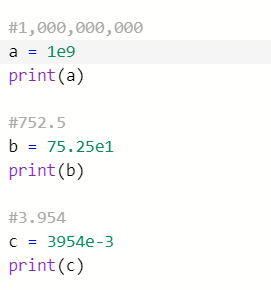
실수형 데이터를 표현하는 방식으로 파이썬에서는 e나 E를 이용한 지수 표현 방식을 이용할 수 있다.
e 다음에 오는 수는 10의 지수부를 의미한다. 예를 들어 1e9는 10의 9제곱 (1,000,000,000) 이 된다.
보통 컴퓨터 시스템은 수 데이터를 처리할 때 2진수를 이용하며, 실수를 처리할 때 부동 소수점(Floating-point) 방식을 이용한다. 오늘날 가장 널리 쓰이는 IEEE754 표준에서는 실수형을 저장하기 위해 4바이트 혹은 8바이트인 고정된 크기의 메모리를 할당하며 이 때문에 현대 컴퓨터는 대체로 실수 정보에 대한 정확도 한계를 가진다.
결과적으로 컴퓨터는 실수를 제대로 표현하지 못한다는 것만 기억하자.

위 코드를 보면 True 가 나올 거 같지만 False 가 나온다.

0.89999... 처럼 부정확한 값이 나오긱 때문이다.
이처럼 소수점 값을 비교하는 작업이 필요하다면 round() 함수를 이용해야한다.
round() 함수는 첫번째 인자는 실수형 데이터고 두번째 인자는 (반올림하고자 하는 위치 -1)이다.
소수 세번째 자리에서 반올림하고 싶으면 round(1,738,2) 이렇게 하면 된다.


2. 리스트 자료형(list)
리스트는 여러 개의 데이터를 연속적으로 담아 처리하기 위해 사용할 수 있다. 다른 프로그래밍 언어의 배열(Array) 기능능을 표함하면서 내부적으로 연결 리스트 자료구조를 채택하고 있어서 append(), remove() 등의 메서드를 지원한다. 파이썬의 리스트는 C++의 STL vector 과 유사하며 리스트 대신에 배열 혹은 테이블이라고 불리기도 한다.
리스트 만들기
리스트는 대괄호([]) 안에 원소를 넣어 초기화하며 쉼표(,)로 원소를 구분한다.

초기화도 다음과 같이 편하게 할 수 있다.

리스트의 인덱싱과 슬라이싱
인덱스 값을 입력하여 리스트의 특정한 원소에 접근하는 것을 인덱싱(Indexing) 이라고 한다.
파이썬에서는 인덱싱 값으로 양,음의 정수를 모두 사용 가능하다. 음의 정수를 넣으면 거꾸로 탐색하게 된다.
또한 리스트에서 연속적인 위치를 갖는 원소들을 가져와야 할 땐 슬라이싱(Slicing)을 이용한다.
대괄호 안에 콜론(:)을 넣어서 시작 인덱스와 (끝 인덱스 -1)을 정할 수 있다.
예를 들어 두번째 원소부터 네번째 원소까지 가져오고 싶다면
print(a[1:4]) 을 하면 된다.
리스트 컴프리헨션
이는 리스트를 초기화하는 방법 중 하나이다. 리스트 컴프리헨션을 이용하면 대괄호([]) 안에 조건문과 반복문을 넣는 방식으로 리스트 초기화가 가능하다.
예를 들어 홀수만 포함하는 리스트를 만들고자 할 때 다음과 같이 할 수 있다.


이는 이차원 배열을 초기화 할때 유용하게 쓰인다.


그리고 이차원 배열을 초기화 할 때는 반드시 리스트 컴프리헨션을 이용해야한다. 아니면 의도치 않은 결과가 나올 수 있다.


보면 하나의 인덱스만 바꾸었다고 생각했는데 3개의 리스트에 인덱스 1에 해당하는 값이 다 5로 바뀐 것을 알 수 있다. 이는 내부적으로 포함된 4개의 리스트가 모두 동일한 객체에 대한 3개의 레퍼런스로 인식되기 때문이다.
리스트 관련 기타 메서드
| 함수명 | 사용법 | 설명 | 시간복잡도 |
| append() | 변수명.append() | 리스트에 원소를 하나 삽입할 때 사용한다. | O(1) |
| sort() | 변수명.sort() 내림차순일때 sort(True) |
정렬 | O(NlogN) |
| reverse() | 변수명.reverse() | 리스트 순서 뒤집기 | O(N) |
| insert() | insert(위치 인덱스, 삽입할 값) | 특정 인덱스 원소 삽입 | O(N) |
| count() | 변수명.count(특정값) | 특정 값을 몇 개 가지는 지 확인할 때 | O(N) |
| remove() | 변수명.remove(특정값) | 특정 값 가지는 원소 제거 여러개면 하나만 제거 |
O(N) |
▷문자열 자료형은 다른 프로그래밍 언어와 유사하여 생략한다.
튜플 자료형
리스트와 거의 유사하지만 다음과 같은 차이가 있다.
-튜플은 한 번 선언된 값을 변경할 수 없다.
-리스트는 대괄호([])을 이용하지만 튜플은 소괄호(())를 이용한다.
즉 튜플은 다음 코드 실행이 불가능하다.


튜플은 그래프 알고리즘 구현때 자주 사용된다.
튜플은 또한 리스트에 비해 상대적으로 공간 효율적이고 각 원소의 성질이 서로 다를 때 주로 사용된다. 흔히 다익스트라 최단 경로 알고리즘에서는 '비용'과 '노드 번호' 라는 서로 다른 성질의 데이터를 함께 튜플로 묶어서 관리하는 것이 관례이다.
사전 자료형
: 사전 자료형은 키(key)와 값(valse)의 쌍을 데이터로 가지는 자료형이다. 사전과 같은 형태인 것이다.
파이썬의 사전 자료혀애은 내부적으로 '해시 테이블'을 이용한다.
리스트보다 훨씬 빠르게 동작한다는 걸 알아두자.


키 데이터만 뽑아서 리스트로 이용할 때는 keys()함수
값 데이터만 뽑아서 리스트로 이용할 때는 values()함수
이용한다.
집합 자료형(Set)
:파이썬에서는 집합(Set) 처리하기 위한 집합 자료형을 제공하고 있다. 집합은 기복전으로 리스트 혹은 문자열을 이용해서 만들어지는 데 다음과 같은 특징이 있다.
-중복을 허용하지 않는다.
-순서가 없다.
특정 원소 유무를 검사하는 시간복잡도는 사전 자료형과 동일하게 O(1)이다.
집합 자료형을 초기화할때는 set()함수를 이용하거나 중괄호({}) 안에 각 원소를 콤마(,) 기준으로 구분해서 넣으면 된다.


집합 자료형의 연산
합집합( | ), 교집합 ( & ), 차집합( - ) 연산이 있다.


집합 자료형 관련 함수
값 추가 add()
한꺼번에 여러 값 추가 update()
특정 값 제거 remove()
시간 복잡도 다 O(1)
'언어 > Python' 카테고리의 다른 글
| 파이썬 입출력(input()) (0) | 2020.09.21 |
|---|
